

Kimi-Audio是什么?
Kimi-Audio 是由kimi開源的通用音頻基礎模型,支持語音識別、音頻理解、音頻轉文本和語音對話等多種任務。它采用集成式架構,包括音頻分詞器、音頻大模型和音頻去分詞器,能夠高效處理多種音頻任務。該模型使用了約1300萬小時的多語言、多場景音頻數據進行預訓練,并通過監督微調進一步提升性能。在十多項基準測試中,Kimi-Audio 總體性能排名第一,尤其在自動語音識別、音頻理解、音頻到文本聊天和語音對話等任務中表現出色。
Kimi-Audio 的模型架構
為實現 SOTA 級別的通用音頻建模, Kimi-Audio 采用了集成式架構設計,包括三個核心組件 —— 音頻分詞器(Audio Tokenizer)、音頻大模型(Audio LLM)、音頻去分詞器(Audio Detokenizer)。
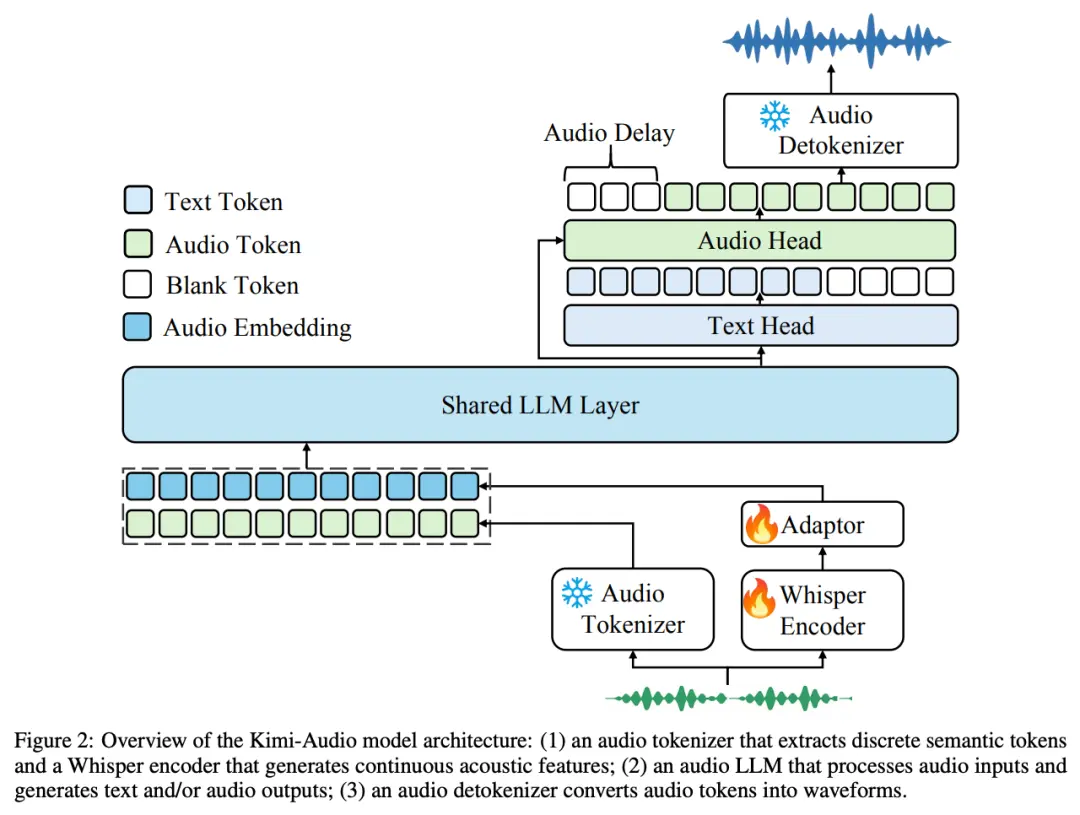
- 音頻分詞器(Audio Tokenizer):將輸入音頻轉化為離散語義 token 和連續聲學向量,幀率為 12.5Hz,結合語義壓縮表示與聲學細節。
- 音頻大模型(Audio LLM):基于共享 Transformer 層,處理多模態輸入,后期分為文本和音頻生成的兩個并行輸出頭。
- 音頻去分詞器(Audio Detokenizer):使用流匹配方法,將離散語義 token 轉化為連貫音頻波形,生成高質量語音。
Kimi-Audio的模型表現
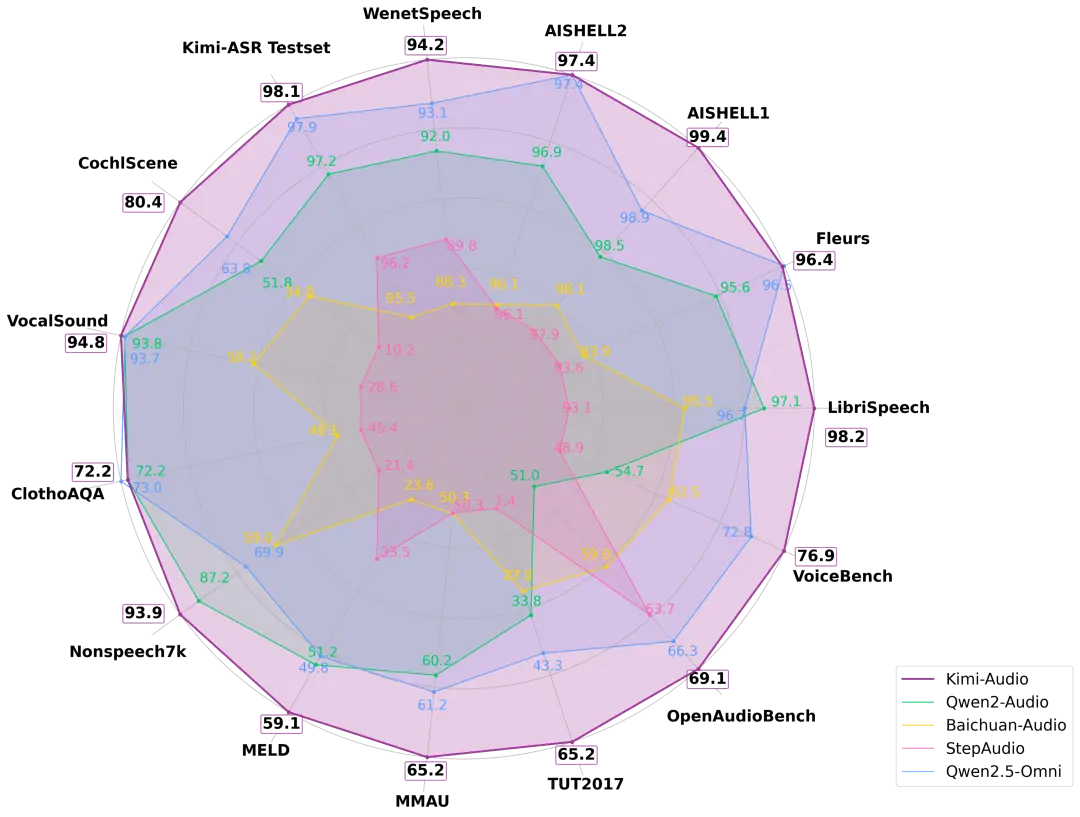
Kimi-Audio 在十多個音頻基準測試中實現了最先進的 (SOTA) 性能,總體性能排名第一。
在 LibriSpeech ASR 測試上,Kimi-Audio 的 WER 僅 1.28%,顯著優于其他模型。VocalSound 測試上,Kimi 達 94.85%,接近滿分 。MMAU 任務中,Kimi-Audio 摘得兩項最高分;VoiceBench 設計評測對話助手的語音理解能力,Kimi-Audio 在所有子任務中得分最高,包括一項滿分。
Kimi-Audio的項目信息
目前,模型代碼、模型檢查點以及評估工具包已經在 Github 上開源。
- GitHub項目鏈接:https://github.com/MoonshotAI/Kimi-Audio
- 技術報告:https://github.com/MoonshotAI/Kimi-Audio/blob/master/assets/kimia_report.pdf
?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
