

ThinkSound 是什么?
ThinkSound 是阿里通義開源的旗下首個音頻生成模型,其核心創新在于首次將 CoT(思維鏈)技術應用于音頻生成領域,通過多模態大語言模型(MLLM)與音頻生成模型的協同,實現 “像專業音效師一樣思考” 的能力,打破傳統 “看圖配音” 的局限,真正基于畫面事件邏輯生成高保真、強同步的空間音頻。
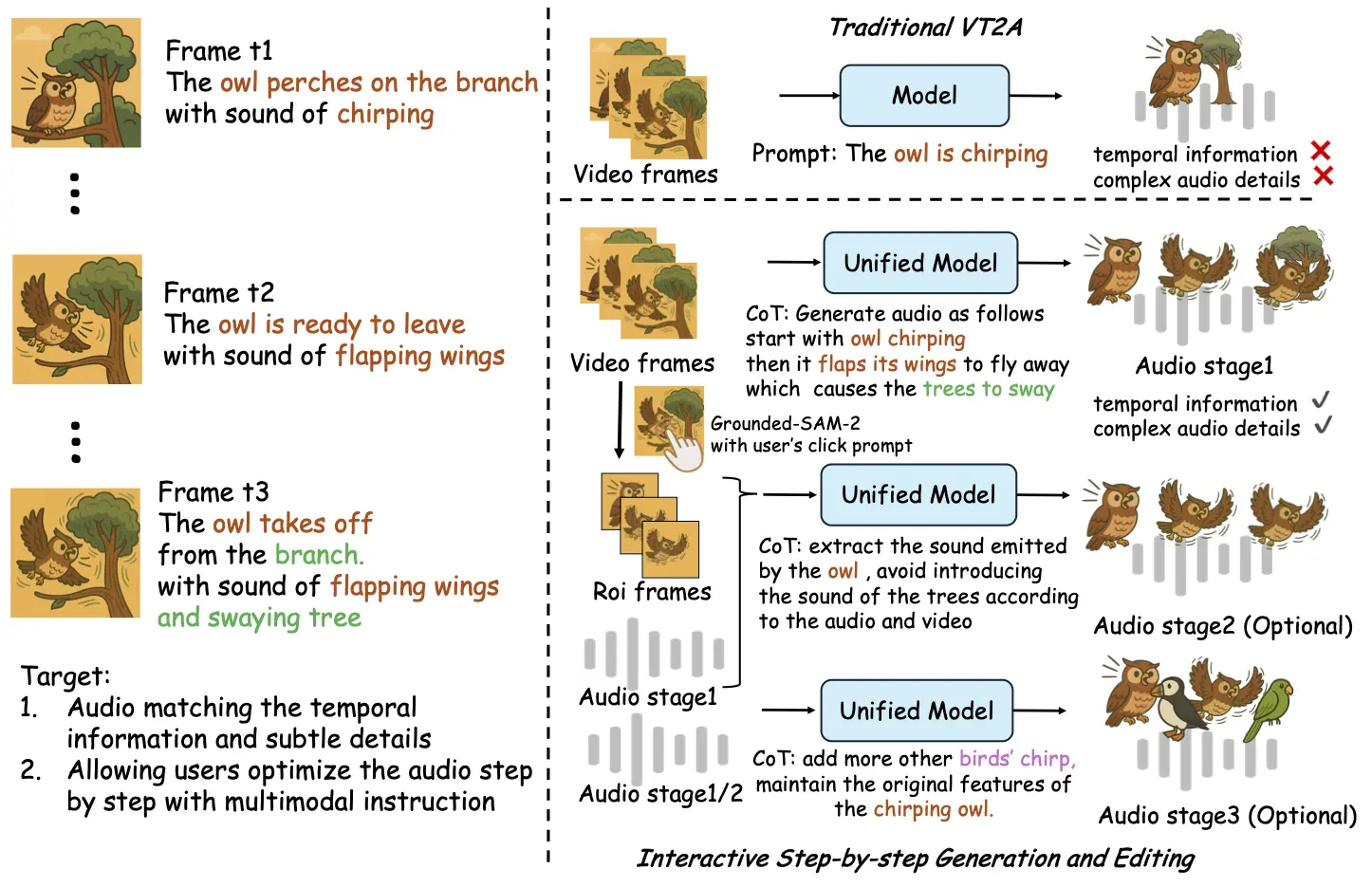
ThinkSound 的主要特性
- Any2Audio:ThinkSound支持任意模態(視頻、文本、音頻或其組合)生成音頻。
- 視頻轉音頻 SOTA:在多個 V2A 基準上取得最新最優結果。
- CoT 驅動推理:基于鏈式思維推理,實現可組合、可控的音頻生成。
- 交互式面向對象編輯:通過點擊視覺對象或文本指令,細化或編輯特定聲音事件。
- 統一框架:單一基礎模型,支持生成、編輯與交互式工作流。
- 全面開源:模型權重、訓練代碼及 Demo 已公開,便于開發者二次開發與部署。
ThinkSound 的應用場景
- 影視與視頻內容創作:為動畫、短視頻、影視片段自動生成貼合畫面的環境音效、物體動作音效,降低專業配音成本。
- 游戲音效設計:根據游戲場景動態生成實時音效(如角色移動、道具交互、場景變換音效),提升沉浸感。
- 多媒體內容編輯:支持用戶通過指令交互式調整音頻,例如為已有視頻添加特定環境音、增強物體音效細節,適用于自媒體、廣告制作等場景。
- 虛擬現實(VR/AR):生成與虛擬場景同步的空間音頻,增強虛擬環境的真實感,應用于 VR 游戲、虛擬培訓等領域。
- 無障礙媒體服務:為視覺障礙用戶生成描述性音效,輔助理解畫面內容,提升多媒體內容的可訪問性。
ThinkSound 的開源地址
- 在線體驗Demo:https://www.modelscope.cn/studios/iic/ThinkSound
- GitHub倉庫:https://github.com/FunAudioLLM/ThinkSound
- Hugging Face模型:https://huggingface.co/spaces/FunAudioLLM/ThinkSound
?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
