


AIHub獲悉,11 月 8 日,阿里巴巴達(dá)摩院公布多模態(tài)大模型 M6 的最新進(jìn)展,其模型參數(shù)已從萬(wàn)億躍遷至 10 萬(wàn)億,規(guī)模遠(yuǎn)超谷歌、微軟發(fā)布的萬(wàn)億級(jí)模型,成為目前全球最大的 AI 預(yù)訓(xùn)練模型。
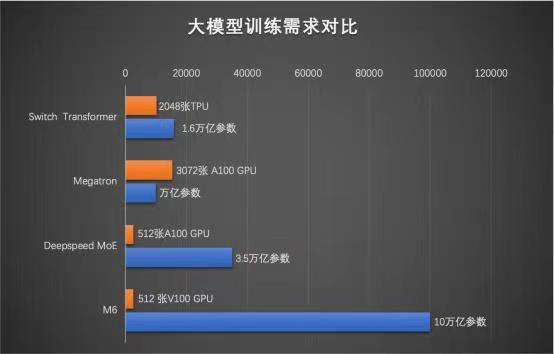
2021年以來(lái),AI訓(xùn)練模型的規(guī)模不斷擴(kuò)大。據(jù)不完全統(tǒng)計(jì),這些大模型包括年初華為發(fā)布的1000億參數(shù)盤(pán)古大模型、1.6萬(wàn)億參數(shù)的Google switch transformer模型、1.75萬(wàn)億參數(shù)的智源悟道2.0智能模型、1.9萬(wàn)億參數(shù)的快手精排模型等。其中,阿里達(dá)摩院M6模型上一次公布的參數(shù)規(guī)模為1萬(wàn)億。
據(jù)了解,與傳統(tǒng)AI相比,大模型擁有成百上千倍“神經(jīng)元”數(shù)量,且預(yù)先學(xué)習(xí)過(guò)海量知識(shí),表現(xiàn)出像人類(lèi)一樣“舉一反三”的學(xué)習(xí)能力。因此,大模型被普遍認(rèn)為是未來(lái)的“基礎(chǔ)模型”,將成下一代AI基礎(chǔ)設(shè)施。
“近年來(lái)人工智能的發(fā)展應(yīng)該從家家戶(hù)戶(hù)‘大煉模型’的狀態(tài)逐漸變?yōu)榘奄Y源匯聚起來(lái),訓(xùn)練超大規(guī)模模型的階段,通過(guò)設(shè)計(jì)先進(jìn)的算法,整合盡可能多的數(shù)據(jù),匯聚大量算力,集約化地訓(xùn)練大模型,供大量企業(yè)使用,這是必然趨勢(shì)。”北京大學(xué)信息科學(xué)技術(shù)學(xué)院教授黃鐵軍說(shuō)。
據(jù)報(bào)道,M6 做到了業(yè)內(nèi)極致的低碳高效,使用 512 GPU 在 10 天內(nèi)即訓(xùn)練出具有可用水平的 10 萬(wàn)億模型。相比去年發(fā)布的大模型 GPT-3,M6 實(shí)現(xiàn)同等參數(shù)規(guī)模,能耗僅為其 1%。
據(jù)悉,M6 是達(dá)摩院研發(fā)的通用性人工智能大模型,擁有多模態(tài)、多任務(wù)能力,其認(rèn)知和創(chuàng)造能力超越傳統(tǒng) AI,尤其擅長(zhǎng)設(shè)計(jì)、寫(xiě)作、問(wèn)答,在電商、制造業(yè)、文學(xué)藝術(shù)、科學(xué)研究等領(lǐng)域有廣泛應(yīng)用前景。
與傳統(tǒng) AI 相比,大模型擁有成百上千倍“神經(jīng)元”數(shù)量,且預(yù)先學(xué)習(xí)過(guò)海量知識(shí),表現(xiàn)出像人類(lèi)一樣“舉一反三”的學(xué)習(xí)能力。因此,大模型被普遍認(rèn)為是未來(lái)的“基礎(chǔ)模型”,將成下一代 AI 基礎(chǔ)設(shè)施。然而,其算力成本相當(dāng)高昂,訓(xùn)練 1750 億參數(shù)語(yǔ)言大模型 GPT-3 所需能耗,相當(dāng)于汽車(chē)行駛地月往返距離。
今年 10 月,M6 再次突破業(yè)界極限,通過(guò)更細(xì)粒度的 CPU offload、共享-解除算法等創(chuàng)新技術(shù),讓收斂效率進(jìn)一步提升 7 倍,這使得模型規(guī)模擴(kuò)大 10 倍的情況下,能耗未顯著增加.這一系列突破極大降低了大模型研究門(mén)檻,讓一臺(tái)機(jī)器訓(xùn)練出一個(gè)千億模型成為可能。
今年,大模型首次支持雙 11。M6 在犀牛智造為品牌設(shè)計(jì)的服飾已在淘寶上線(xiàn);憑借流暢的寫(xiě)作能力,M6 正為天貓?zhí)摂M主播創(chuàng)作劇本;依靠多模態(tài)理解能力,M6 正在增進(jìn)淘寶、支付寶等平臺(tái)的搜索及內(nèi)容認(rèn)知精度。

M6生成的未來(lái)感汽車(chē)圖
達(dá)摩院智能計(jì)算實(shí)驗(yàn)室負(fù)責(zé)人周靖人表示,“接下來(lái),我們將深入研究大腦認(rèn)知機(jī)理,致力于將M6的認(rèn)知力提升至接近人類(lèi)的水平,比如,通過(guò)模擬人類(lèi)跨模態(tài)的知識(shí)抽取和理解方式,構(gòu)建通用的人工智能算法底層框架;另一方面,不斷增強(qiáng)M6在不同場(chǎng)景中的創(chuàng)造力,產(chǎn)生出色的應(yīng)用價(jià)值。”
- Facebook正式改名Meta,扎克伯格All in元宇宙,開(kāi)啟新征程;
- 微軟加入元宇宙大戰(zhàn):將Mesh直接植入Teams中,將不同元宇宙粘合起來(lái);
- 中科深智完成B輪融資,利用AI技術(shù)打造元宇宙內(nèi)容生產(chǎn)中臺(tái)。
-
全球第一!阿里達(dá)摩院AI訓(xùn)練模型M6參數(shù)破10萬(wàn)億,遠(yuǎn)超谷歌、微軟; - 微軟宣布推出Azure OpenAI服務(wù),為開(kāi)發(fā)者帶來(lái)GPT-3模型,幫助企業(yè)建構(gòu)更聰明的應(yīng)用;
- 全球最大規(guī)模人工智能巨量模型 “源1.0”正式開(kāi)源!2457 億模型參數(shù),超越美國(guó)GPT-3模型。
3.AI人物:
- 又一巨星隕落!北大計(jì)算語(yǔ)言學(xué)家俞士汶去世,助力漢語(yǔ)走向信息時(shí)代;
- 《科學(xué)之路》| 圖靈獎(jiǎng)得主楊立昆人工智能十問(wèn):AI會(huì)統(tǒng)治人類(lèi)嗎?
白色大數(shù)據(jù)科技互聯(lián)網(wǎng)宣傳中文微信公眾號(hào)二維碼-1.png)
