

OpenAI 最近宣布了其聊天機(jī)器人 ChatGPT 的一次重大更新,這也是自引入 GPT-4 以來最大的一次改進(jìn)。新的 ChatGPT 現(xiàn)在不僅可以理解文本,還能“看、聽、說”。具體來說,它能理解口語,用合成的聲音回應(yīng),并處理圖像。
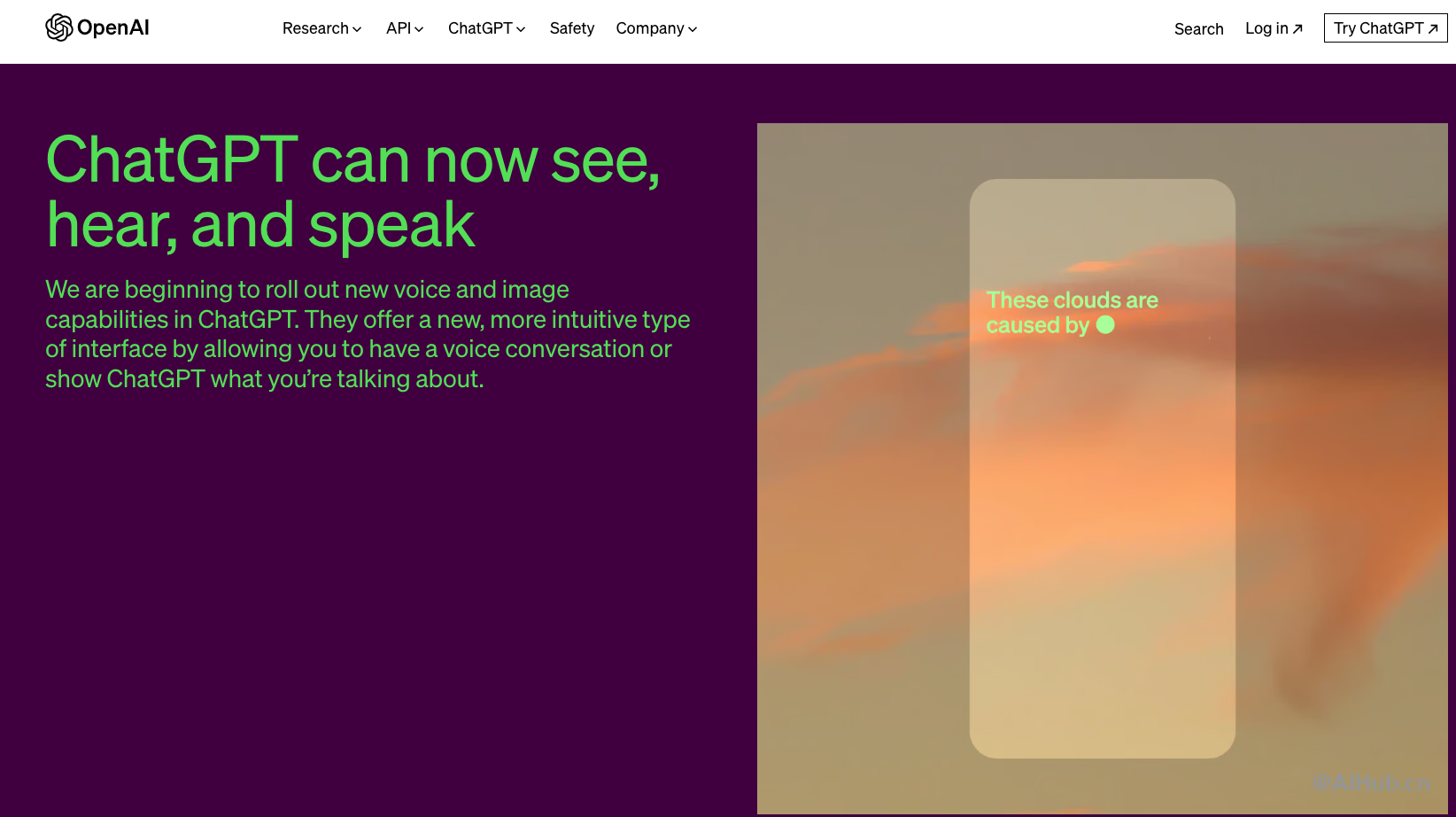
這次更新是自引入 GPT-4 以來 OpenAI 最大的一次改進(jìn)。用戶可以選擇使用五種不同的合成聲音與 ChatGPT 進(jìn)行語音對話,并向其分享圖片并突出顯示重點或分析區(qū)域(例如:「這些是什么類型的云?」)。
這些變化將在未來兩周內(nèi)推出給付費用戶。雖然語音功能將僅限于 iOS 和 Android 應(yīng)用程序,但圖像處理功能將適用于所有平臺。
OpenAI 在其網(wǎng)站上提供了一個宣傳視頻,展示了與 ChatGPT 的交流演示:用戶詢問如何升起自行車座椅,并提供了照片、使用手冊和用戶工具箱的圖片。ChatGPT 會做出反應(yīng)并建議用戶如何完成這一過程。
那么它是如何工作的呢?OpenAI 并未公布 GPT-4 或其多模態(tài)功能如何在后臺運(yùn)行的技術(shù)細(xì)節(jié),但根據(jù)其他公司(包括 OpenAI 合作伙伴微軟)的已知人工智能研究,多模態(tài)人工智能模型通常會將文本和圖像轉(zhuǎn)換到一個共享的編碼空間,從而使它們能夠通過相同的神經(jīng)網(wǎng)絡(luò)處理各種類型的數(shù)據(jù)。OpenAI 可以使用 CLIP 在視覺數(shù)據(jù)和文本數(shù)據(jù)之間架起一座橋梁,將圖像和文本表征整合到同一個潛在空間(一種矢量化的數(shù)據(jù)關(guān)系網(wǎng))中。這種技術(shù)可以讓 ChatGPT 跨文本和圖像進(jìn)行上下文推理,不過這只是一種推測。
此次大規(guī)模推廣新功能正值聊天機(jī)器人領(lǐng)導(dǎo)者之間人工智能競賽日益升級之際,如 OpenAI、微軟、谷歌和?Anthropic?等公司都在努力鼓勵消費者采納生成式人工智能技術(shù),并競相發(fā)布新的聊天機(jī)器人應(yīng)用程序和特性。谷歌已經(jīng)宣布了 Bard 聊天機(jī)器人的一系列更新,微軟則為必應(yīng)添加了視覺搜索功能。
據(jù) PitchBook 報道,今年早些時候,微軟擴(kuò)大了對 OpenAI 的投資——追加 100 億美元——使其成為本年度最大的人工智能投資。據(jù)報道,今年 4 月,這家初創(chuàng)公司完成了 3 億美元的股票出售,估值在 270 億至 290 億美元之間,投資方包括紅杉資本(Sequoia Capital)和 Andreessen Horowitz 等公司。
專家們對人工智能生成的合成聲音提出了關(guān)注,這種技術(shù)可以讓用戶獲得更自然的體驗,但也可能會產(chǎn)生更令人信服的深度偽造。網(wǎng)絡(luò)威脅行為者和研究人員已經(jīng)開始探索如何利用深度偽造來滲透網(wǎng)絡(luò)安全系統(tǒng)。
OpenAI 在周一發(fā)布公告時承認(rèn)了這些問題,并表示合成聲音是「與我們直接合作過的配音演員創(chuàng)作」的,而不是從陌生人那里收集來的。
該公司還未提供有關(guān) OpenAI 將如何使用消費者語音輸入或如何保護(hù)數(shù)據(jù)(如果使用的話)的信息。該公司服務(wù)條款規(guī)定,「在適用法律允許范圍內(nèi)」,消費者擁有其輸入內(nèi)容所有權(quán)。
OpenAI 引述了其有關(guān)語音交互指南中所述內(nèi)容,其中指出?OpenAI 不會保留音頻剪輯,并且這些剪輯本身并不用于改進(jìn)模型。但該公司還指出,在此過程中轉(zhuǎn)錄被視為輸入,并可能用于改進(jìn)大型語言模型。
