

2月5日 消息:CodeFuse-VLM是一個(gè)支持多種視覺(jué)模型和語(yǔ)言大模型的框架,用戶(hù)可以根據(jù)自己的需求搭配不同的Vision Encoder和LLM。
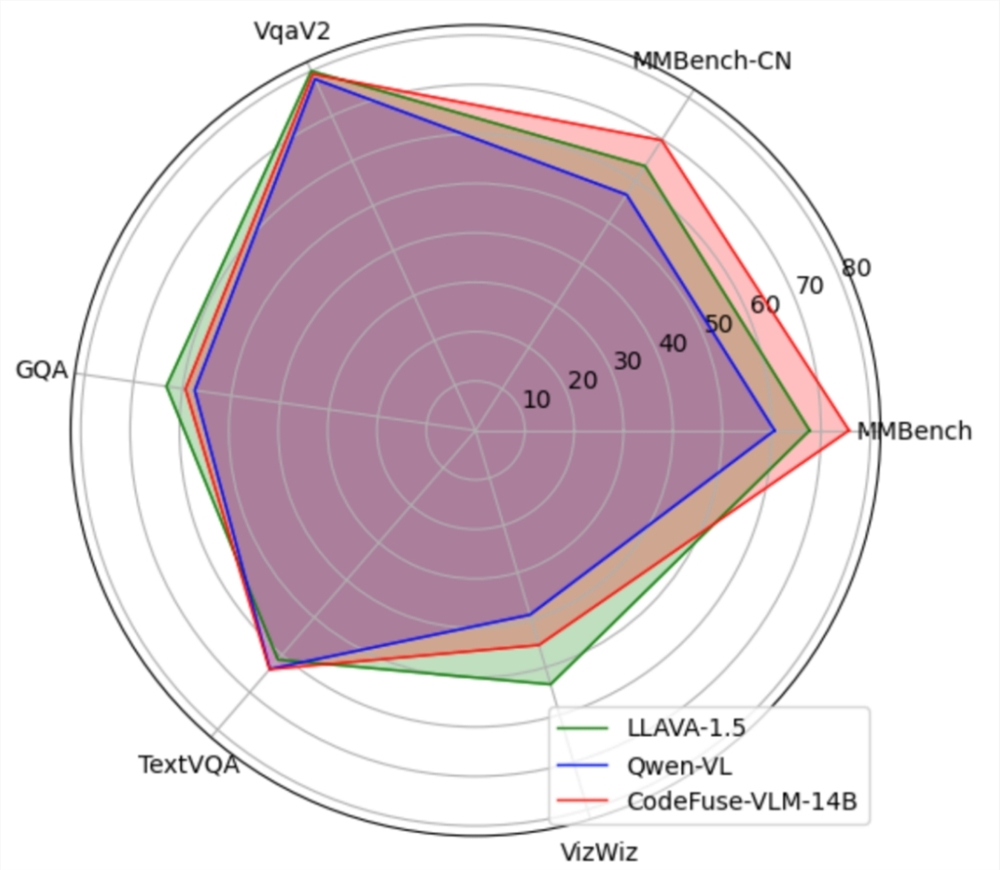
CodeFuse-VLM-14B模型在多個(gè)通用和代碼任務(wù)上的性能超過(guò)LLAVA-1.5和Qwen-VL。
該框架還支持高效的PEFT微調(diào),能有效提升微調(diào)訓(xùn)練速度并降低對(duì)資源的需求。
此外,CodeFuse-VLM還被用于訓(xùn)練網(wǎng)頁(yè)圖片到前端代碼的多模態(tài)大模型,提高了前端工程師的開(kāi)發(fā)效率。
CodeFuse-MFT-VLM 項(xiàng)目地址:
https://github.com/codefuse-ai/CodeFuse-MFT-VLM
CodeFuse-VLM-14B模型地址:
https://modelscope.cn/models/ss41979310/CodeFuse-VLM-14B/files
?版權(quán)聲明:如無(wú)特殊說(shuō)明,本站所有內(nèi)容均為AIHub.cn原創(chuàng)發(fā)布和所有。任何個(gè)人或組織,在未征得本站同意時(shí),禁止復(fù)制、盜用、采集、發(fā)布本站內(nèi)容到任何網(wǎng)站、書(shū)籍等各類(lèi)媒體平臺(tái)。否則,我站將依法保留追究相關(guān)法律責(zé)任的權(quán)利。
