

4月5日凌晨,Open?AI在官網(wǎng)宣布新增6個全新微調(diào)API功能,以擴(kuò)展自定義模型,幫助企業(yè)、開發(fā)人員更好地構(gòu)建特定領(lǐng)域、精細(xì)化的ChatGPT應(yīng)用。
這些功能包括:基于Epoch的檢查點(diǎn)創(chuàng)建、Playground新功能、第三方集成、全面驗證指標(biāo)、超參數(shù)配置和更詳細(xì)的微調(diào)儀表板改進(jìn)。
新的微調(diào)API功能適用于GPT-4/Turbo、GPT-3.5等系列模型。
詳細(xì)微調(diào)API教程:https://platform.openai.com/docs/guides/fine-tuning
微調(diào)API?6個新功能介紹
2023年8月22日,OpenAI首次推出了基于GPT-3.5 Turbo的微調(diào)API功能,使企業(yè)、開發(fā)人員可以使用自己的數(shù)據(jù),結(jié)合業(yè)務(wù)用例構(gòu)建專屬ChatGPT。
經(jīng)過幾個月的時間,全球數(shù)千個組織借助OpenAI的微調(diào)API功能,訓(xùn)練了數(shù)十萬個自定義模型實(shí)現(xiàn)降本增效。
例如,全球知名招聘平臺Indeed希望新增一項功能,向求職者發(fā)送個性化推薦,根據(jù)求職者的技能、經(jīng)驗和偏好突出顯示相關(guān)工作。
Indeed通過GPT-3.5 Turbo 進(jìn)行了微調(diào),生成了高質(zhì)量和更準(zhǔn)確的個性化推薦。每月向求職者發(fā)送的消息也從最初不到100萬條,大幅度增加到大約2000萬條。
今天,OpenAI推出了6個新的微調(diào)API功能,以幫助開發(fā)人員更好地使用微調(diào)。
基于Epoch的檢查點(diǎn)創(chuàng)建:在深度學(xué)習(xí)模型的訓(xùn)練過程中,基于Epoch的檢查點(diǎn)創(chuàng)建是一項非常重要的功能。每個Epoch結(jié)束時或者在特定的Epoch間隔時,系統(tǒng)會自動保存當(dāng)前模型的狀態(tài),包括模型的參數(shù)(權(quán)重和偏置)和優(yōu)化器的狀態(tài)。
如果訓(xùn)練過程因為意外原因(比如硬件故障、電源中斷等)被中斷,檢查點(diǎn)允許我們從最后保存的狀態(tài)恢復(fù)訓(xùn)練,而不是從頭開始。
所以,OpenAI新增的基于 Epoch 的檢查點(diǎn)創(chuàng)建功能,可以極大減少模型的重復(fù)訓(xùn)練,尤其是在過度擬合的情況下。
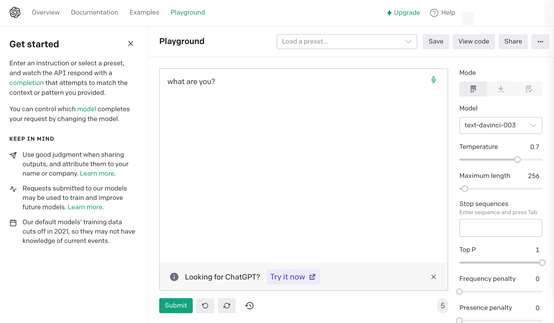
Comparative Playground:Playground是OpenAI在2022年發(fā)布的一個可視化模型比較平臺,提供了一個交互式的在線環(huán)境,允許用戶輸入指令或提示詞,然后將其發(fā)送給多個語言模型查看它們的輸出結(jié)果。
本次,OpenAI新增一個并排的Playground UI,用于比較不同模型質(zhì)量和性能,同時允許對多個模型的輸出進(jìn)行人工評估或根據(jù)單個提示微調(diào)快照。
第三方集成:新的微調(diào)支持與第三方平臺集成,讓開發(fā)人員與堆棧的其余部分共享詳細(xì)的微調(diào)數(shù)據(jù)。
全面驗證指標(biāo):能夠計算整個驗證數(shù)據(jù)集(而不是采樣批次)的損失和準(zhǔn)確性等指標(biāo),從而更好地了解模型質(zhì)量。
超參數(shù)配置:可以從儀表板配置可用的超參數(shù),而不僅僅是通過API或SDK。
微調(diào)儀表板改進(jìn):包括配置超參數(shù)、查看更詳細(xì)的訓(xùn)練指標(biāo)以及從以前的配置重新運(yùn)行作業(yè)等功能。這也就是說,開發(fā)人員在微調(diào)的過程中可以掌控更詳細(xì)、直觀的微調(diào)數(shù)據(jù)。

什么是微調(diào)?
微調(diào)(Fine-tuning)是一種在預(yù)訓(xùn)練大模型的基礎(chǔ)上,進(jìn)一步優(yōu)化和調(diào)整模型參數(shù)的技術(shù),使模型更好地適應(yīng)特定業(yè)務(wù)場景。這個過程中,模型的參數(shù)會進(jìn)行微小的調(diào)整。
微調(diào)的主要流程包括:
初始化,使用預(yù)訓(xùn)練語言模型的參數(shù)對新模型進(jìn)行初始化;添加輸出層,根據(jù)下游任務(wù)的目標(biāo)(文本生成、內(nèi)容摘要等)在預(yù)訓(xùn)練模型的頂層添加相應(yīng)的輸出層;微調(diào)訓(xùn)練,使用帶標(biāo)注的私有數(shù)據(jù),以較小的學(xué)習(xí)率對整個模型進(jìn)行訓(xùn)練,直至模型在驗證集上的指標(biāo)達(dá)到理想效果。
例如,我們希望GPT3.5模型在法律業(yè)務(wù)上的表現(xiàn)更好、更專業(yè),可以用海量法律數(shù)據(jù)集對模型進(jìn)行微調(diào)。經(jīng)過微調(diào),模型學(xué)習(xí)到如何更好地解讀、生成和預(yù)測法律問題。
如何進(jìn)行微調(diào)?
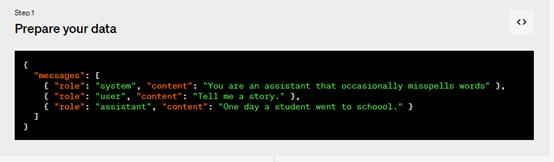
1、準(zhǔn)備數(shù)據(jù),創(chuàng)建一組多樣化的演示對話,類似于要求模型在實(shí)際輸出中的對話。數(shù)據(jù)集中的每個示例都應(yīng)該與OpenAI的聊天完成 API 格式相同的對話,特別是消息列表,其中每條消息都有角色、內(nèi)容和可選名稱。
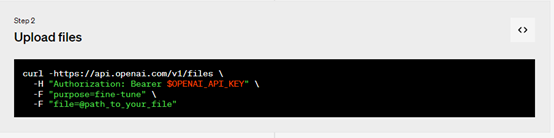
2、上傳文件
3、創(chuàng)建微調(diào)作業(yè),使用 OpenAI SDK開始進(jìn)行大規(guī)模數(shù)據(jù)訓(xùn)練、微調(diào)。訓(xùn)練模型可能需要幾分鐘或幾小時,具體取決于模型和數(shù)據(jù)集大小。
模型訓(xùn)練完成后,創(chuàng)建微調(diào)作業(yè)的用戶將收到一封確認(rèn)電子郵件。
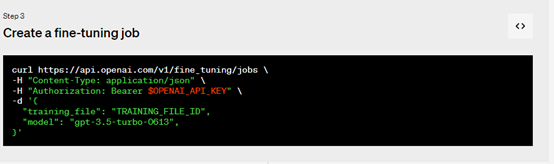
除了創(chuàng)建微調(diào)作業(yè)外,開發(fā)者還可以列出現(xiàn)有作業(yè)、檢索作業(yè)狀態(tài)或取消作業(yè)。
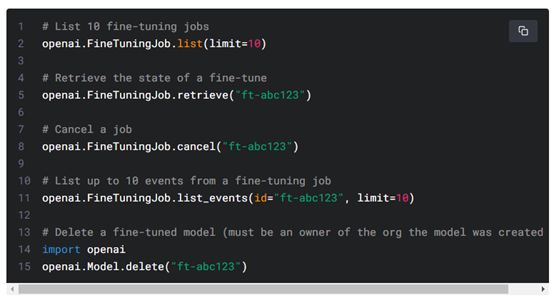
4、使用微調(diào)模型,微調(diào)作業(yè)完成后模型可以投入使用了。

在某些情況下,用戶的微調(diào)模型可能需要幾分鐘才能準(zhǔn)備好處理請求。如果對模型的請求超時或找不到模型名稱,可能是因為模型仍在加載中,可在幾分鐘后重試。
