

2025年7月4日,阿里通義實(shí)驗(yàn)室正式發(fā)布了旗下首個(gè)音頻生成模型——ThinkSound。這一突破性技術(shù)首次將思維鏈(CoT)概念應(yīng)用于音頻生成領(lǐng)域,讓AI可以像“專業(yè)音效師”一樣理解畫(huà)面事件與聲音的關(guān)系,突破了傳統(tǒng)音頻生成的局限。
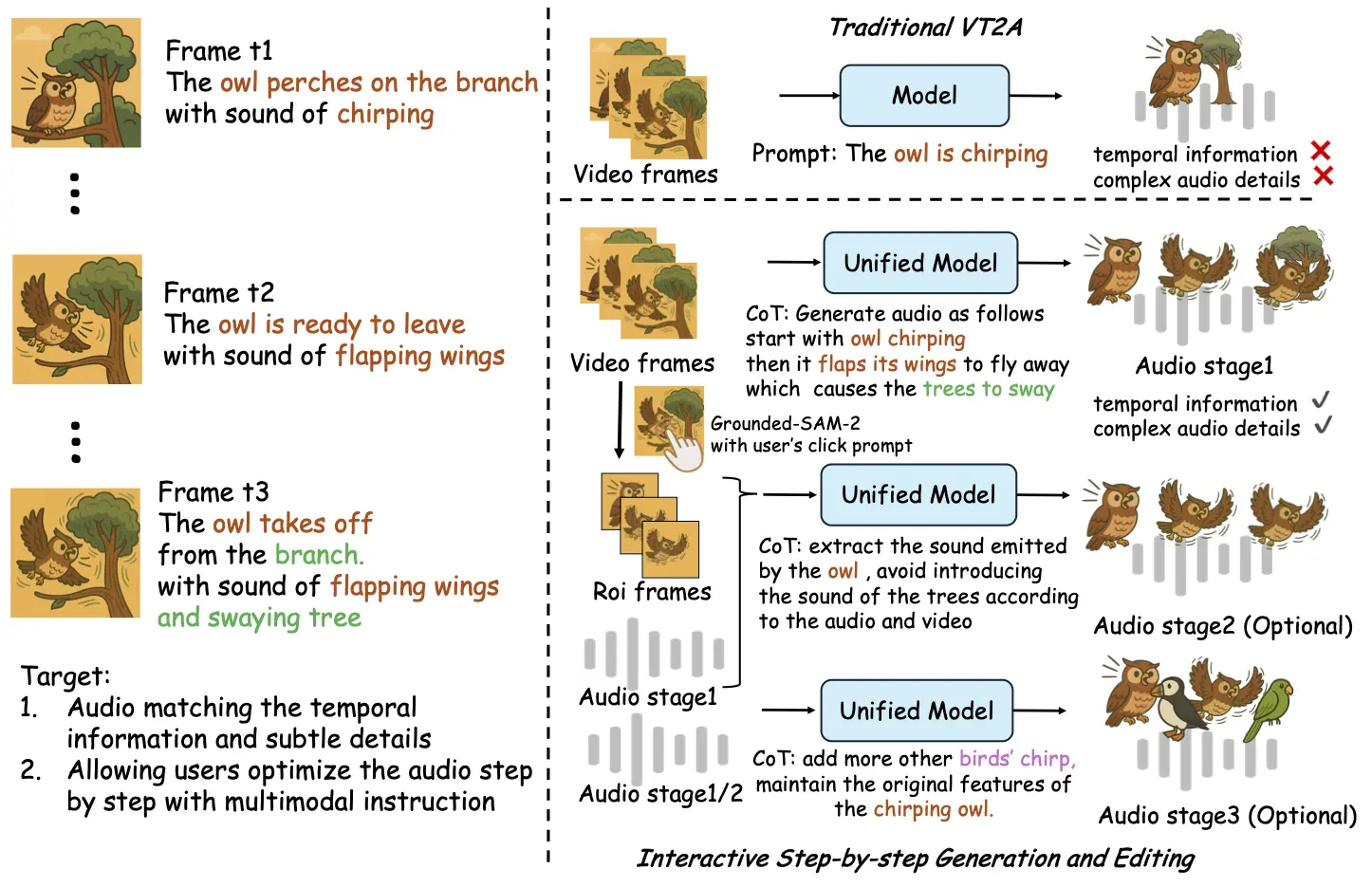
ThinkSound的核心亮點(diǎn)在于其精確的空間音頻生成能力,不僅能夠?yàn)橐曨l畫(huà)面配音,更能根據(jù)畫(huà)面內(nèi)容做出深入的推理,生成高保真、時(shí)序精確的音效。這一技術(shù)的發(fā)布,將大大推動(dòng)影視、游戲等創(chuàng)意行業(yè)的發(fā)展,提升音效與畫(huà)面之間的語(yǔ)義連貫性和動(dòng)態(tài)表現(xiàn)。
與傳統(tǒng)的音頻生成技術(shù)相比,ThinkSound能夠根據(jù)三階段推理從整體畫(huà)面到具體物體,再到用戶指令的響應(yīng)逐步生成音效。其背后,阿里通義實(shí)驗(yàn)室還構(gòu)建了一個(gè)名為AudioCoT的多模態(tài)音頻數(shù)據(jù)集,融合了來(lái)自多個(gè)知名音頻平臺(tái)的2531.8小時(shí)高質(zhì)量樣本,涵蓋動(dòng)物叫聲、機(jī)械運(yùn)作等多個(gè)現(xiàn)實(shí)場(chǎng)景,為模型的訓(xùn)練提供了豐富素材。
目前,ThinkSound已正式開(kāi)源,并將面向全球開(kāi)發(fā)者和創(chuàng)作者開(kāi)放,進(jìn)一步推動(dòng)智能音效技術(shù)的發(fā)展。通過(guò)這一開(kāi)源平臺(tái),用戶可以體驗(yàn)到更精細(xì)化、個(gè)性化的音頻生成,未來(lái)可能會(huì)在虛擬現(xiàn)實(shí)、增強(qiáng)現(xiàn)實(shí)等領(lǐng)域發(fā)揮重要作用。
隨著ThinkSound的發(fā)布,AI在創(chuàng)意產(chǎn)業(yè)的應(yīng)用范圍將得到進(jìn)一步擴(kuò)展,音效創(chuàng)作將不再僅僅依賴人工,未來(lái)的聲音設(shè)計(jì)可能會(huì)由AI與創(chuàng)作者共同完成,開(kāi)辟出音效生成的新天地。
