

SWE-Lancer是什么?
SWE-Lancer 是 OpenAI 開源的一個全新評估大模型代碼能力的測試基準,通過端到端測試來模擬真實的開發任務,旨在更全面地評估大語言模型在軟件工程任務中的表現,尤其是處理復雜、全棧任務的能力。其測試數據集包含 1488 個來自 Upwork 平臺上 Expensify 開源倉庫的真實開發任務,涵蓋獨立開發和管理任務,總價值高達 100 萬美元。
SWE-Lancer的主要特點
- 端到端測試:SWE-Lancer通過模擬完整的用戶交互流程,測試不僅驗證單個功能的實現,還確保整個開發任務的連貫性和正確性。這種方式更加貼近現實中的軟件開發場景。
- 真實開發任務:SWE-Lancer包含來自Upwork平臺的1488個開發任務,這些任務涉及修復漏洞、實現功能、選擇最佳解決方案等,分為獨立開發任務和軟件工程管理任務兩類。
- 高價值任務:數據集總價值達到 100萬美元,任務內容涵蓋了高難度、高價值的軟件工程挑戰,旨在測試大模型是否能夠解決復雜的實際問題。
- 全面評估:測試不僅評估模型解決單個問題的能力,還考察模型如何應對復雜的系統交互、數據庫操作等多方面挑戰,提供更為全面的能力評估。
- 現實性強:SWE-Lancer通過模擬真實開發場景和任務,使得模型測試更具實際意義,評估結果能夠真實反映大模型在軟件開發中的應用潛力與局限性。
SWE-Lancer的數據集
SWE-Lancer數據集一共包含1488個來自Upwork平臺上Expensify開源庫的真實軟件開發任務,一共分為獨立貢獻者和軟件工程管理任務兩大類。
獨立開發任務一共有764個,價值414,775美元,主要模擬個體軟件工程師的職責,例如,實現功能、修復漏洞等。在這類任務中,模型會得到問題文本描述涵蓋重現步驟、期望行為、問題修復前的代碼庫檢查點以及修復目標。
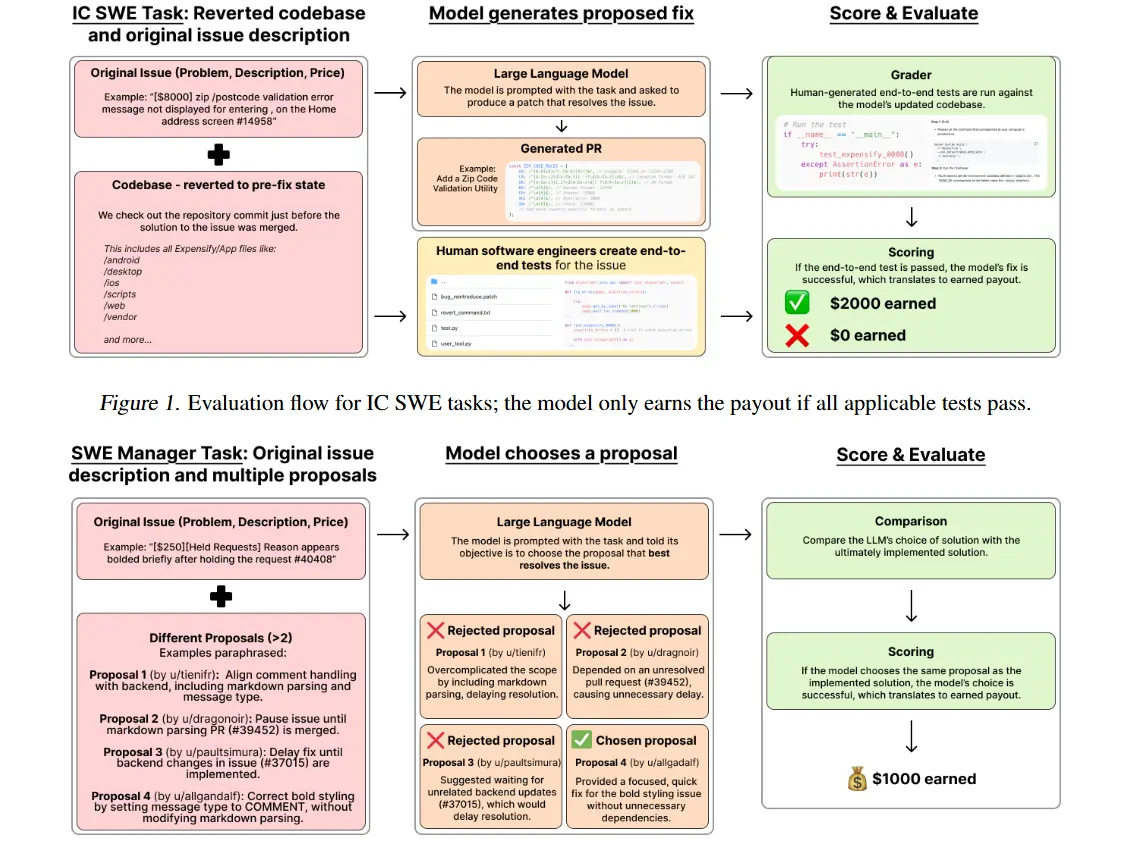
軟件管理任務,有724個,價值585,225美元。模型在此類任務中扮演軟件工程經理的角色,需要從多個解決任務的提案中挑選最佳方案。例如,在一個關于在iOS上實現圖像粘貼功能的任務中,模型要從不同提案里選擇最適宜的方案。
首批SWE-Lancer測試結果
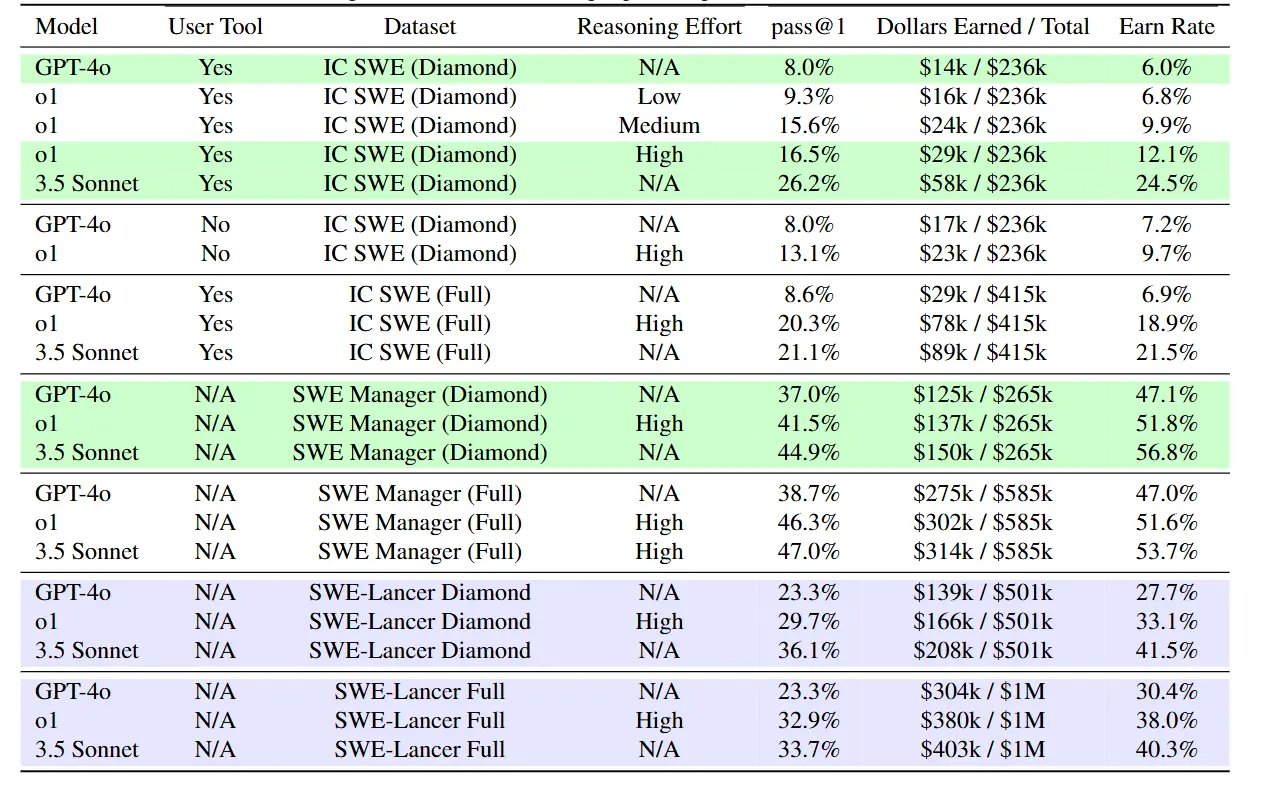
OpenAI使用了GPT-4o、o1和Claude3.5Sonnet在SWE-Lancer進行了測試,結果顯示:
- 在獨立開發任務中,表現最好的 Claude 3.5 Sonnet 的通過率僅為 26.2%,而 GPT-4o 的通過率僅為 8%。
- 在軟件工程管理任務中,Claude 3.5 Sonnet 的通過率為 44.9%,GPT-4o 的通過率為 37.0%。
- 在高價值、復雜任務中,模型的通過率普遍低于 30%,表明模型在處理復雜任務時仍比人類差很多。
如何使用SWE-Lancer?
SWE-Lancer的開源資源如下:
?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
