

F5-TTS是什么?
F5-TTS是一款基于“流匹配(Flow Matching)”的全非自回歸文本到語音(TTS)轉換系統,由上海交通大學、劍橋大學和吉利汽車研究院聯合開發。該系統采用先進的架構,具備零樣本聲音克隆、多語言合成、情感控制等功能,能夠生成高度自然、流暢的語音。通過在超過10萬小時的多語言數據上進行訓練,F5-TTS 展現出卓越的語音生成能力,支持長文本合成、實時推理和多場景應用。

F5-TTS的功能特性
- 零樣本聲音克隆:F5-TTS 具備強大的零樣本聲音克隆功能,通過僅15秒的音頻樣本即可快速克隆目標聲音,無需大量數據支持,生成的語音自然流暢。
- 多語言合成:F5-TTS 支持中英文等多語言的無縫切換,能夠生成自然流暢的多語言語音輸出。
- 情感控制:該系統可以根據用戶需求生成帶有不同情感的語音,從憤怒到喜悅再到悲傷,使語音更加生動富有表現力。
- 高效推理與快速生成:F5-TTS 的推理速度極快,實時因素(RTF)達到0.15,能夠迅速生成高質量的語音。
- 速度控制:F5-TTS 允許用戶根據文本總時長靈活調整語音生成的速度,使其適應不同場景的需求。
- 并行生成:與傳統的逐步生成方式不同,F5-TTS 采用并行生成技術,同時處理多個步驟,從而顯著加快語音生成速度。
- 長文本合成:F5-TTS 能夠處理長文本語音合成,確保生成的語音自然、連貫。它特別適合有聲書、新聞播報等場景,可以連續生成高質量的語音而不影響其流暢性。
- 大規模數據訓練:F5-TTS 基于10萬小時的多語言數據集進行訓練,保證了其在多語言、多場景中的卓越表現,能夠處理復雜的語境和語言結構。
- 流匹配架構:F5-TTS 采用了流匹配架構,簡化了復雜的生成流程,如持續時間模型和音素對齊,同時提高了語音生成的精確性和自然性。
F5-TTS相關資源地址
- F5-TTS論文地址:https://arxiv.org/abs/2410.06885??
- F5-TTS模型下載:https://huggingface.co/SWivid/F5-TTS??
- F5-TTS Demo:https://huggingface.co/spaces/mrfakename/E2-F5-TTS??
- F5-TTS GitHub 代碼:https://github.com/SWivid/F5-TTS
- F5-TTS項目地址:https://swivid.github.io/F5-TTS/
如何使用F5-TTS?
1、在線使用
你通過官網直接體驗其多語言語音生成和速度、情感控制功能。
訪問F5-TTS體驗官網,上傳原始音色音頻,最好是說話的音頻,也可以錄制自己的聲音上傳。然后輸入需要轉成語音的文本。同步生成,最后就可生成帶預期音色的音頻了。
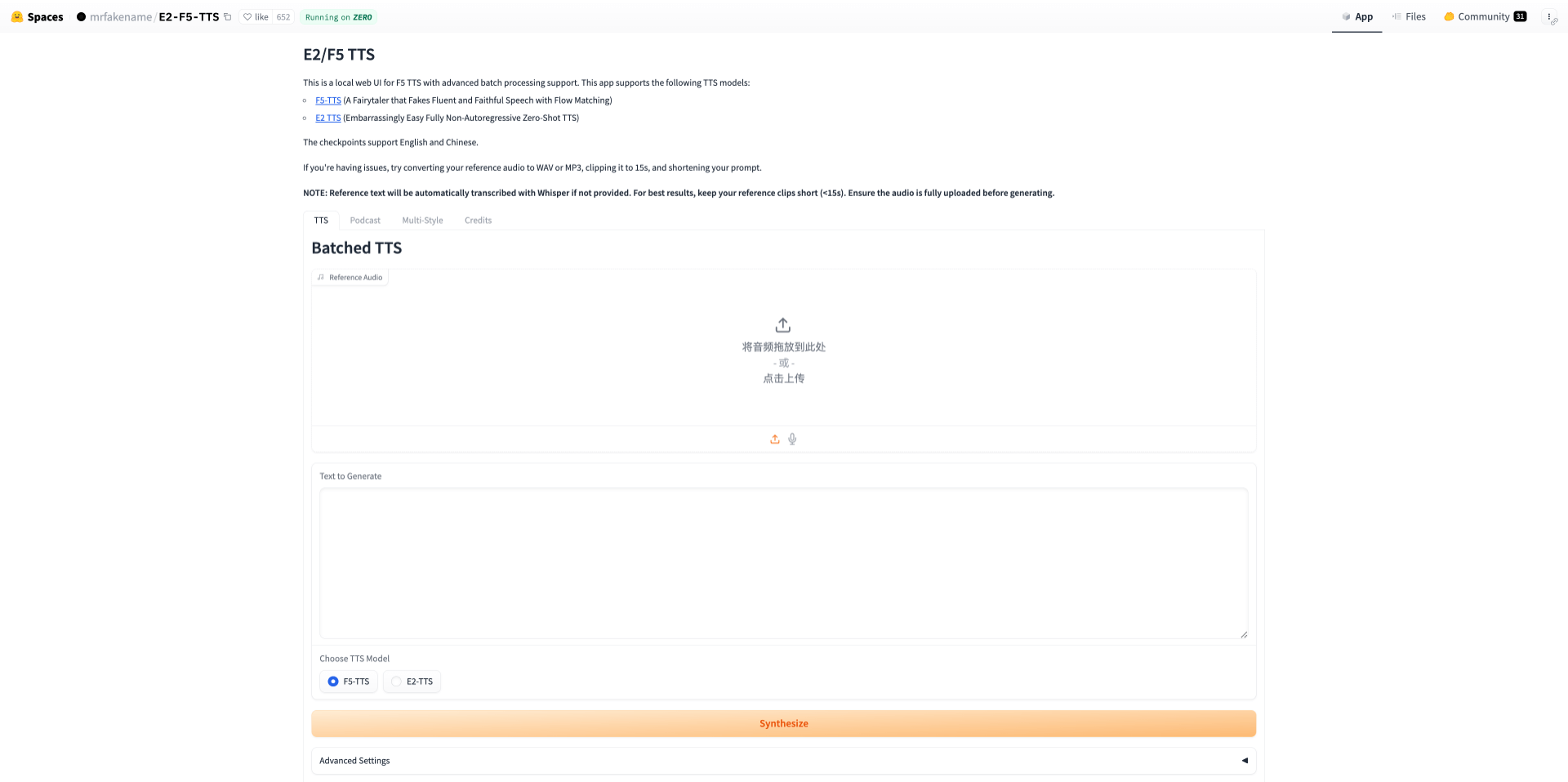
2、本地部署
本地部署,需要保證GPU資源(算力)充足及Python環境。
F5-TTS項目地址(部署教程):https://github.com/SWivid/F5-TTS
- 克隆項目
git?clone?https://github.com/SWivid/F5-TTS.gitcd?F5-TTS
- 安裝項目依賴包
pip?install?-r requirements.txt- 安裝合適的CUDA包(英偉達顯卡必須)
pip?install?torch==2.3.0+cu118?--extra-index-url?https://download.pytorch.org/whl/cu118pip?install?torchaudio==2.3.0+cu118?--extra-index-url?https://download.pytorch.org/whl/cu118
- 準備數據集并訓練、推理、運行項目
python?gradio_app.py?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
