

一、AudioGPT是什么?
AudioGPT是一個理解和生成語音、音樂、聲音等內容的多模態AI系統,將Chat-GPT與音頻基礎模型相結合,以處理復雜的音頻信息和支持口頭對話,在多輪對話中展現出強大的音頻理解和生成能力,使用戶可以輕松地創建豐富多樣的音頻內容。
由浙江大學、北京大學、卡內基梅隆大學和中國人民大學的研究人員提出的全新音頻理解與生成系統 AudioGPT。
AudioGPT 以 Chat-GPT 充當負責對話與控制的大腦,語音基礎模型協同以完成跨模態轉換、以及音頻 (語音、音樂、背景音、3D 說話人) 模態的理解、生成,能夠解決 20 + 種多語種、多模態的 AI 音頻任務。
功能示例:


二、AudioGPT可以做什么?
它還可以執行許多其他任務,例如:
- 音頻轉錄;
- 圖像中的音樂和聲音;
- 來自音頻文件的說話頭部視頻。
還有更多:
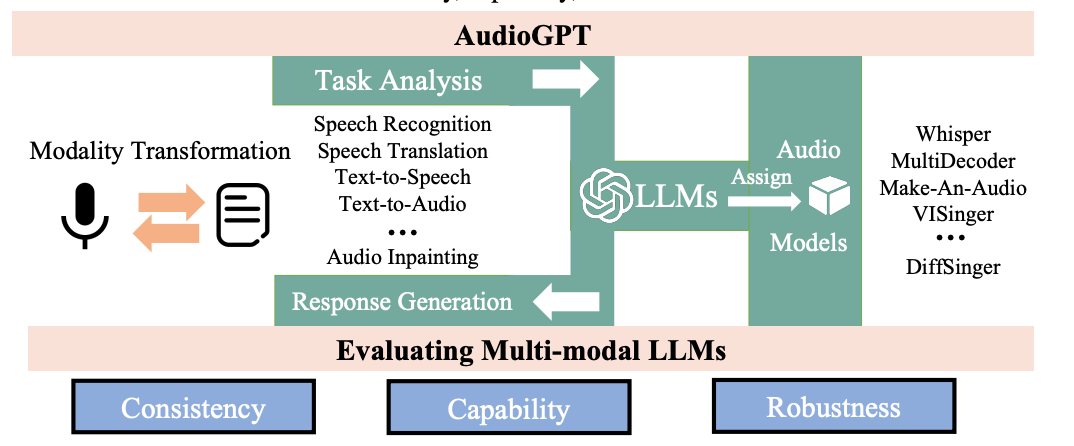
三、工作流程
AudioGPT 包括四個關鍵步驟:
- 模態轉換:使用語音識別系統將語音輸入轉換為文本。
- 任務分析:使用Chat-GPT 了解用戶的請求。
- 模型分配:從一組 17 個模型中選擇合適的 AI 模型來處理特定任務。
- 響應生成:以不同的方式(音頻、文本、圖像、視頻)生成輸出并將其呈現給用戶。?
四、AudioGPT局限性
盡管 AudioGPT 具有令人印象深刻的功能,但它也有一些局限性:
- 它不是專門為音樂而建的。
- 它仍在進行中,在任務分配和理解用戶需求方面還有一些改進空間。
對音樂制作未來的影響
AudioGPT 等 AI 作曲和制作助手有可能極大地改變音樂家的工作方式。通過使用音樂模型擴展 AudioGPT 或創建單獨的 MusicGPT,并開發用于集成到數字音頻工作站 (DAW) 中的插件,AI 驅動的音頻工具可能成為音樂家的寶貴資源。這將增強而不是取代人類在音樂制作中的創造力和表現力。
五、如何使用?
- 試用模型:https://huggingface.co/spaces/AIGC-Audio/AudioGPT
- GitHub地址:https://github.com/AIGC-Audio/AudioGPT
- 論文地址:https://arxiv.org/abs/2304.12995
本模型暫時只能用于非商業用途。
?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
