

CogAgent是什么?
CogAgent是一個由清華大學智譜AI開發的基于CogVLM改進的新型視覺語言模型(VLM)。該模型專門設計用于理解和導航圖形用戶界面(GUI)。它采用了低分辨率和高分辨率圖像編碼器的雙編碼器系統,能夠處理和理解復雜的GUI元素和文本內容。
CogAgent-18B擁有110億的視覺參數和70億的語言參數,?支持1120*1120分辨率的圖像理解。在CogVLM的能力之上,它進一步擁有了GUI圖像Agent的能力。
CogAgent-18B 在9個經典的跨模態基準測試中實現了最先進的通用性能,包括 VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, 和 POPE 測試基準。它在包括AITW和Mind2Web在內的GUI操作數據集上顯著超越了現有的模型。
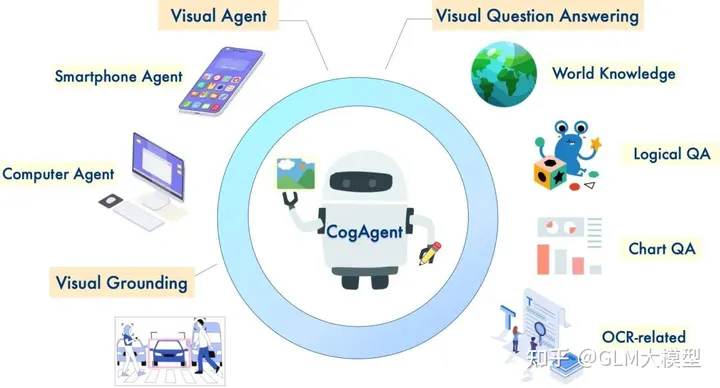
CogAgent可以做什么?
CogAgent的主要功能是提高GUI的交互效率和準確性。它能夠識別和解釋小型GUI元素和文本,這對于有效的GUI交互至關重要。CogAgent在多個任務中表現優于現有的基于大型語言模型的方法,尤其是在PC和Android平臺的GUI導航方面。此外,它還在多個文本豐富和一般視覺問答基準上表現出色。潛在應用包括自動化GUI操作(如點擊按鈕、輸入文本和選擇菜單)、提供GUI幫助和指導,以及開發新的GUI設計和交互方式。
CogAgent 的潛在應用包括:
- 自動化 GUI 操作,例如點擊按鈕、輸入文本和選擇菜單。
- 提供 GUI 幫助和指導,例如解釋功能和提供操作說明。
- 開發新的 GUI 設計和交互方式。
CogAgent 仍處于早期開發階段,但其潛在影響是巨大的。該模型有可能徹底改變我們與計算機交互的方式。
如何使用CogAgent?
CogAgent對外開放了論文、代碼,提供了在線體驗功能:
?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
