

混元DiT是什么?
混元DiT是騰訊最新開源的文生圖AI模型,采用了與Sora、Stable Diffusion 3相同的DiT(Diffusion With Transformer)架構(gòu),支持中英文雙語輸入及理解,參數(shù)量達到15億。它是業(yè)界首個中文原生的DiT架構(gòu)文生圖開源模型,可以作為視頻等多模態(tài)視覺生成的基礎(chǔ)。
混元DiT的主要特點
- 中英雙語DiT架構(gòu):混元DiT采用了與Sora和Stable Diffusion 3相同的DiT架構(gòu),這是一種結(jié)合了擴散模型和Transformer架構(gòu)的技術(shù)。擴散模型是一種生成模型,能夠生成高保真度的圖像,而Transformer架構(gòu)則是一種在自然語言處理(NLP)領(lǐng)域非常成功的模型結(jié)構(gòu)。
- 中文元素理解:混元DiT支持中文和英文的輸入及理解,尤其對中文語言和文化元素有更好的理解和生成能力。
- 長文本理解:混元DiT能分析和理解長篇文本中的信息并生成相應(yīng)藝術(shù)作品。
- 細粒度語義理解:混元DiT能捕捉文本中的細微之處,從而生成完美符合用戶需要的圖片。
- 多輪對話文生圖:混元DiT可以在多輪對話中通過與用戶持續(xù)協(xié)作,精煉并完善的創(chuàng)意構(gòu)想。
- 開源和免費商用:模型已在Hugging Face平臺及Github上發(fā)布,包含模型權(quán)重、推理代碼、模型算法等,可供免費商用。


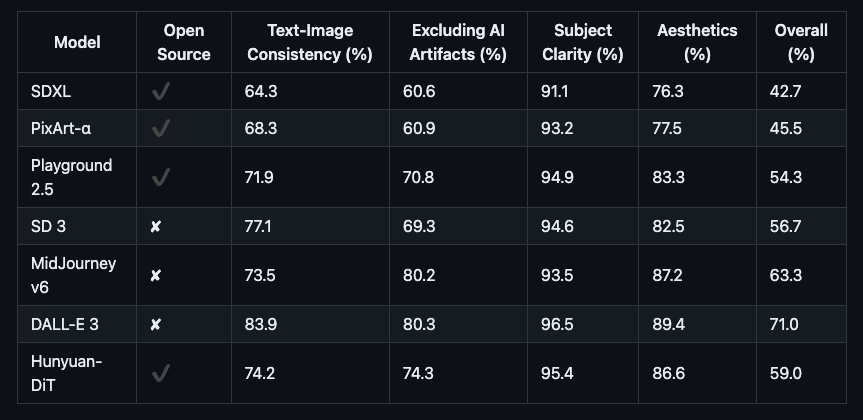
混元DiT的性能表現(xiàn)
為了全面比較HunyuanDiT與其他模型的生成能力,研究團隊構(gòu)建了4個維度的測試集,包括文本圖像一致性、排除AI偽影、主題清晰度、審美。超過50名專業(yè)評估人員進行評估。
評測數(shù)據(jù)顯示,其效果超過現(xiàn)有的開源Stable Diffusion模型,屬于國際領(lǐng)先水平。
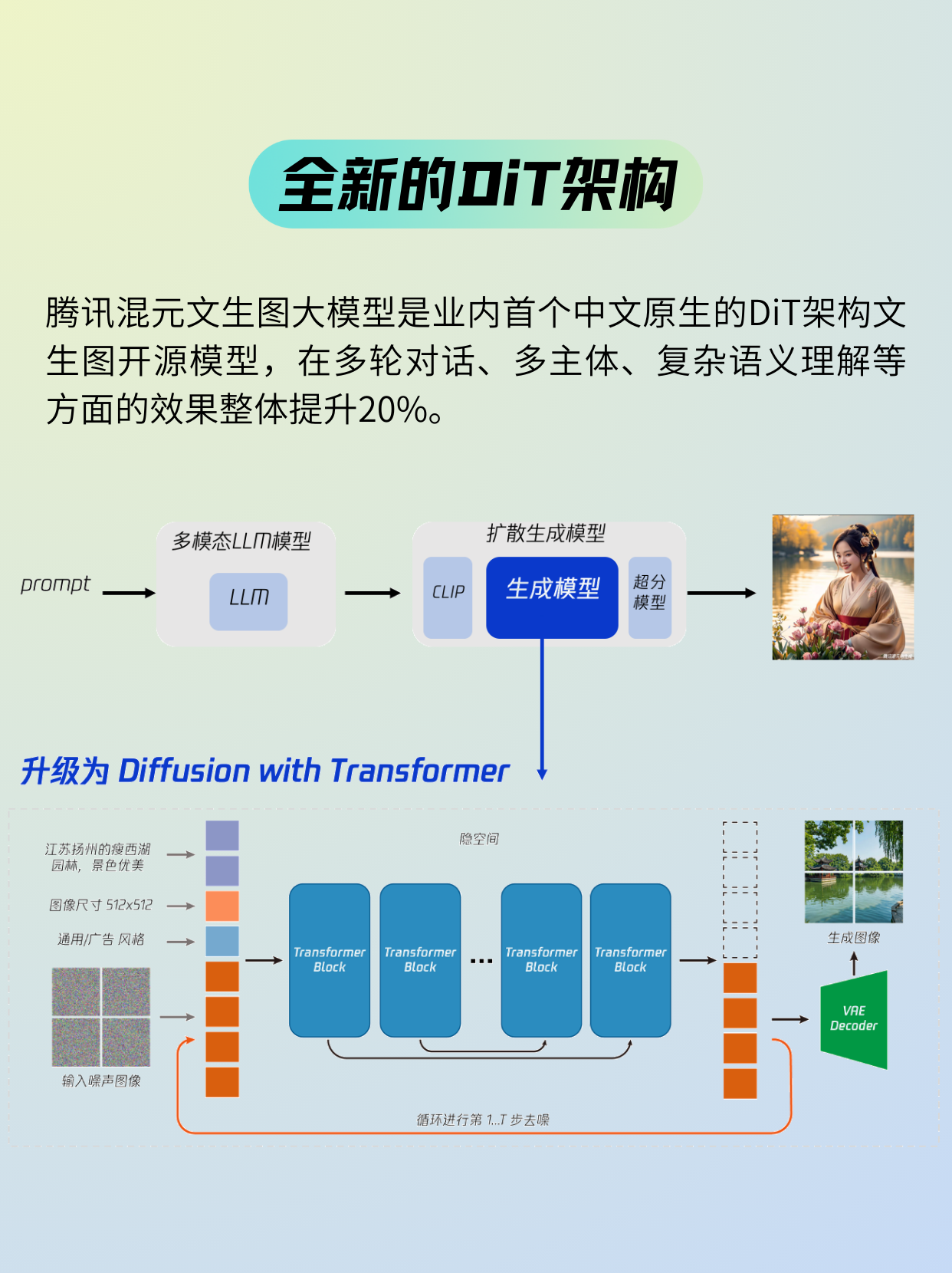
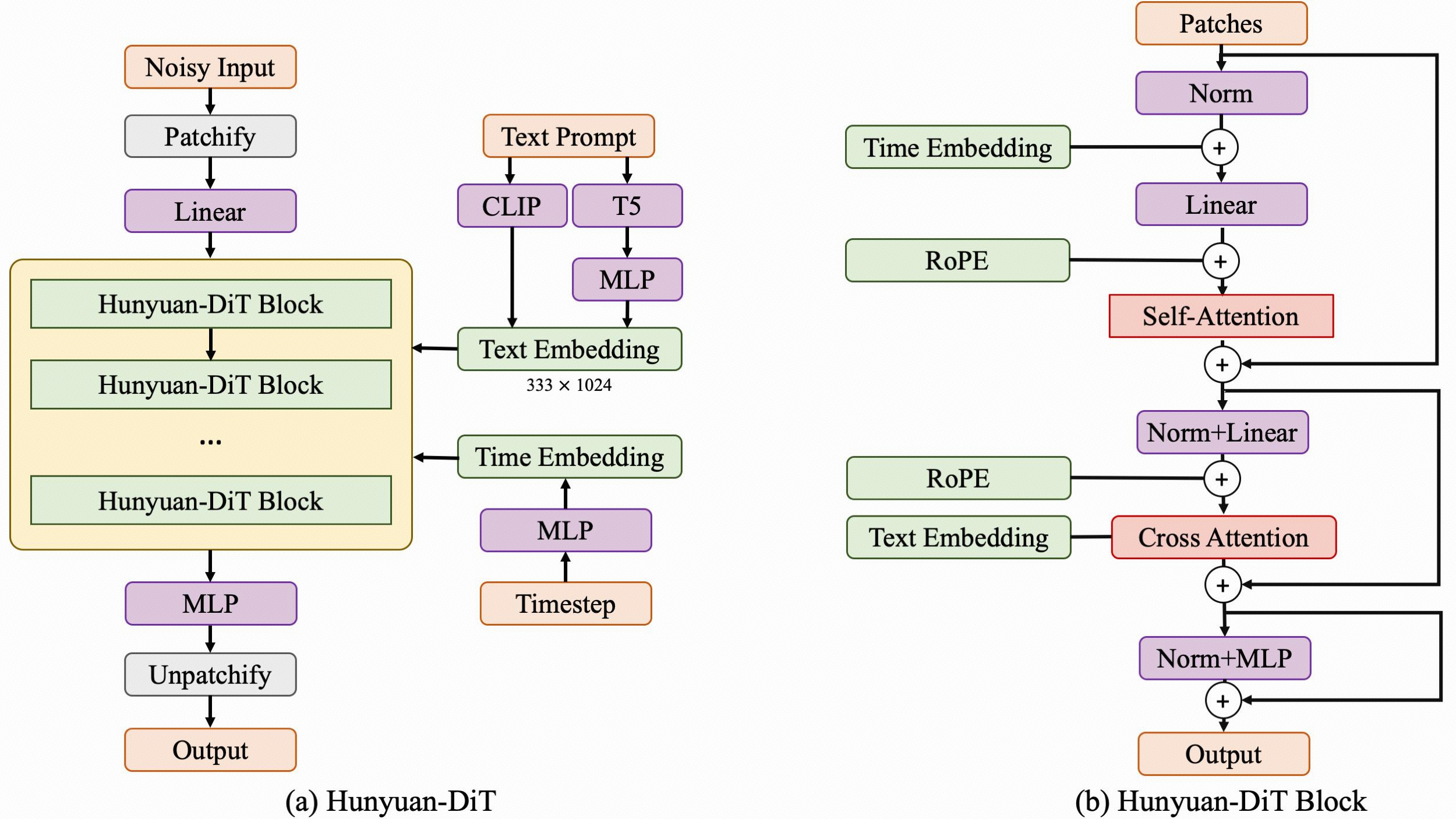
混元DiT的技術(shù)架構(gòu)
混元DiT使用預訓練的變分自編碼器(VAE)將圖像壓縮到低維潛在空間中,并訓練擴散模型以學習擴散模型的數(shù)據(jù)分布。混元DiT的擴散模型是用Transformer參數(shù)化的。為了對文本提示進行編碼,混元DiT利用了預先訓練的雙語(英文和中文)CLIP和多語言T5編碼器的組合。
如何使用混元DiT?
目前,混元DiT已在 Hugging Face 平臺及 Github 上發(fā)布,包含模型權(quán)重、推理代碼、模型算法等完整模型,可供企業(yè)與個人開發(fā)者免費商用。
- 官方項目地址:https://dit.hunyuan.tencent.com/
- Hugging Face模型:https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
- Github源碼:https://github.com/Tencent/HunyuanDiT
- 技術(shù)報告:https://tencent.github.io/HunyuanDiT/asset/Hunyuan_DiT_Tech_Report_05140553.pdf
另外,騰訊也基于混元DiT開發(fā)了一個AI生圖產(chǎn)品:騰訊混元生圖,感興趣的話,可以去體驗下。
?版權(quán)聲明:如無特殊說明,本站所有內(nèi)容均為AIHub.cn原創(chuàng)發(fā)布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發(fā)布本站內(nèi)容到任何網(wǎng)站、書籍等各類媒體平臺。否則,我站將依法保留追究相關(guān)法律責任的權(quán)利。
