

Open-Sora是什么?
Open-Sora 1.0是由Colossal-AI團隊開源的類Sora架構視頻生成模型,采用Diffusion Transformer(DiT) 架構,能夠根據文本提示生成高質量視頻內容。該模型通過三個階段的訓練流程實現,包括大規模圖像預訓練、視頻預訓練和微調。Open-Sora 1.0的開源降低了視頻生成的技術門檻,為AI在視頻創作領域的應用開辟了新路徑。
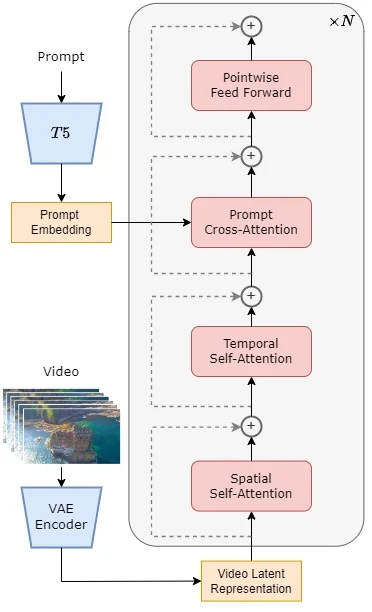
Open-Sora的模型架構
Open-Sora 1.0的模型架構基于當前流行的Diffusion Transformer (DiT) 架構,并針對視頻生成任務進行了特別的擴展。以下是該模型架構的關鍵組成部分:
- 預訓練的VAE (Variational Autoencoder):用于對視頻數據進行壓縮,將數據編碼到一個潛在空間中,以便與文本嵌入一起用于后續的生成過程。
- 文本編碼器:將輸入的文本提示轉換為嵌入向量,這些向量在生成過程中與視頻特征結合。
- STDiT (Spatial Temporal Diffusion Transformer):這是模型的核心,它結合了空間注意力和時間注意力機制,用于建模視頻幀之間的時序關系。STDiT通過串行地在二維空間注意力模塊上疊加一維時間注意力模塊來實現這一點。
- 交叉注意力模塊:在時間注意力模塊之后,該模塊用于對齊文本的語義信息,與全注意力機制相比,這種結構顯著降低了訓練和推理的計算開銷。
- 訓練和推理流程:在訓練階段,首先使用VAE的編碼器壓縮視頻數據,然后在潛在空間中結合文本嵌入訓練STDiT擴散模型。在推理階段,從VAE的潛在空間中采樣高斯噪聲,并與提示詞嵌入一起輸入到STDiT中,得到去噪后的特征,最后通過VAE的解碼器生成視頻。
Open-Sora 1.0的模型架構設計允許它有效地生成與文本描述相匹配的視頻內容,同時保持較低的計算成本和高效的訓練過程。這種結合了空間和時間信息的混合注意力機制是實現高質量視頻生成的關鍵。
Open-Sora的功能特性
Open-Sora 的主要功能特性包括:
- 完整的Sora復制架構解決方案:提供從數據處理到訓練和推理的全過程解決方案。
- 動態分辨率支持:允許直接訓練任何分辨率的視頻,無需進行縮放處理。
- 多種模型結構:實現了包括adaLN-zero、交叉注意力和上下文條件(token concat)在內的多種常見的多模態模型結構。
- 多種視頻壓縮方法:用戶可以選擇使用原始視頻、VQVAE(視頻原生模型)或SD-VAE(圖像原生模型)進行訓練。
- 并行訓練優化:包括與Colossal-AI兼容的AI大模型系統優化能力,以及與Ulysses和FastSeq的混合序列并行性。
- 性能優化:針對Sora類訓練任務的特點(小模型但序列長度異常長),Open-Sora引入了兩種不同的序列并行方法,可以與ZeRO一起實現混合并行。
- 成本降低:相比基線解決方案,Open-Sora在600K序列長度下提供了超過40%的性能提升和成本降低。
- 序列長度擴展:Open-Sora能夠訓練更長的序列,達到819K+,同時保證更快的訓練速度。
這些特性使得Open-Sora成為一個高性能、低成本的視頻生成模型開發解決方案,有助于推動AI視頻生成技術的發展和應用。
如何使用Open-Sora?
- Open-Sora項目主頁:https://hpcaitech.github.io/Open-Sora/
- Open-Sora開源地址:https://github.com/hpcaitech/Open-Sora
?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
