

Qwen2.5是什么?
Qwen是阿里巴巴集團Qwen團隊研發的大語言模型和大型多模態模型系列。目前,大語言模型已升級至Qwen2.5版本。無論是語言模型還是多模態模型,均在大規模多語言和多模態數據上進行預訓練,并通過高質量數據進行后期微調以貼近人類偏好。Qwen具備自然語言理解、文本生成、視覺理解、音頻理解、工具使用、角色扮演、作為AI Agent進行互動等多種能力。
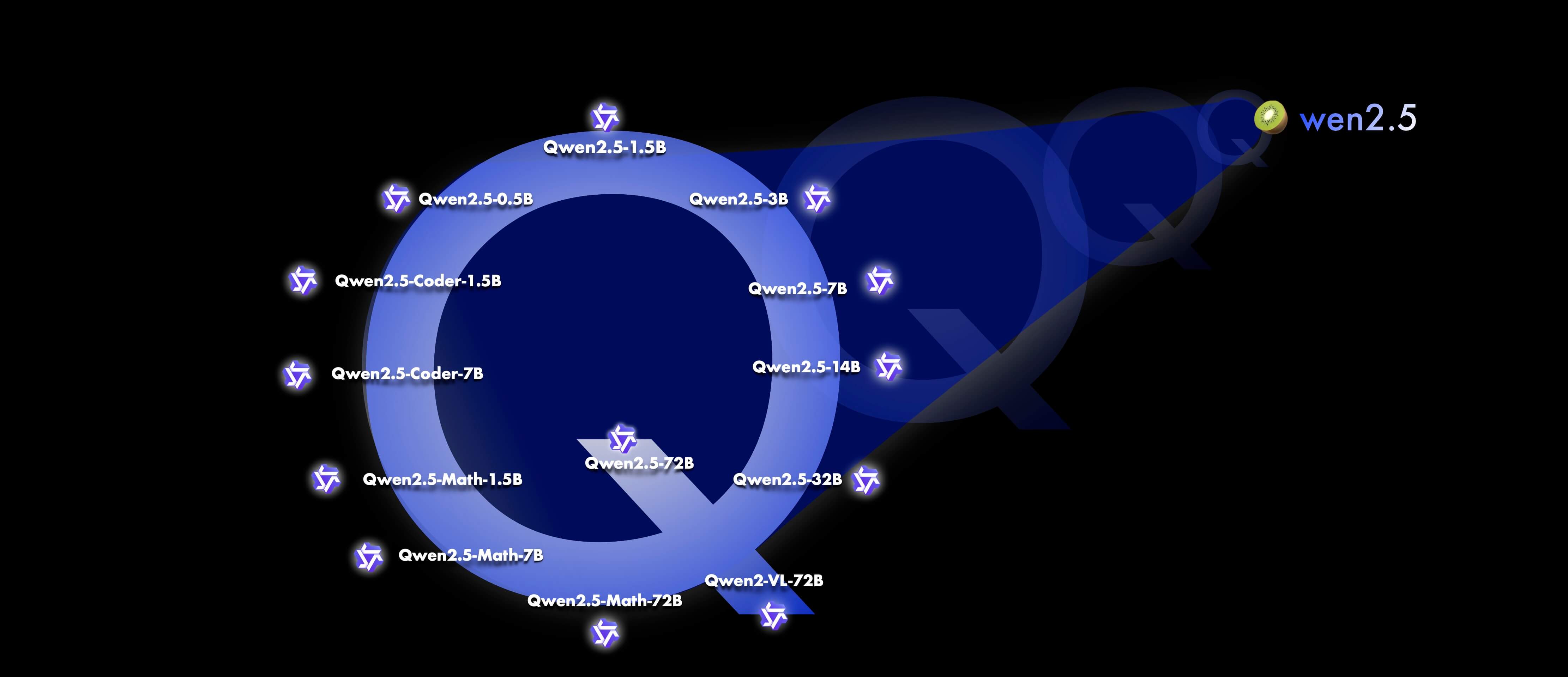
Qwen2.5的主要特點
- 參數規模多樣:易于使用的僅解碼器稠密語言模型,提供?0.5B?、1.5B?、3B?、7B?、14B?、32B?和?72B?共7種參數規模的模型,并且有基模型和指令微調模型兩種變體(其中“ B ”表示“十億”, 72B 即為 720 億)
- 大規模數據預訓練:利用我們最新的數據集進行預訓練,包含多達 18T tokens (其中“ T ”表示“萬億”, 18T 即為 18 萬億)
- 長文本處理能力:在遵循指令、生成長文本(超過 8K tokens )、理解結構化數據(例如,表格)以及生成結構化輸出特別是 JSON 方面有了顯著改進
- 指令遵循與改進:更加適應多樣化的系統提示,增強了角色扮演的實現和聊天機器人的背景設置。
- 上下文理解:支持最多達?128K?tokens 的上下文長度,并能生成多達?8K?tokens 的文本。
- 多語言支持:支持超過?29?種語言,包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韓文、越南文、泰文、阿拉伯文等。
如何使用Qwen2.5?
Qwen2.5既提供了開源模型,也開放了API服務,幫助你快速開發或集成生成式AI功能。
1、開源版本:
- 開源地址:https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
- Github:https://github.com/QwenLM/Qwen2.5?tab=readme-ov-file
- 在線demo:https://huggingface.co/spaces/Qwen/Qwen2.5
2、API服務
如果不想進行繁瑣的部署,阿里還開放了旗艦模型Qwen-Plus 和 Qwen-Turbo的API。
API地址:https://help.aliyun.com/zh/model-studio/developer-reference/what-is-qwen-llm

?版權聲明:如無特殊說明,本站所有內容均為AIHub.cn原創發布和所有。任何個人或組織,在未征得本站同意時,禁止復制、盜用、采集、發布本站內容到任何網站、書籍等各類媒體平臺。否則,我站將依法保留追究相關法律責任的權利。
