

Stable Audio是什么?
Stable Audio是Stability AI 推出的AI生成音樂平臺,你只需要輸入描述性文本提示以及所需的音頻長度即可生成高質(zhì)量的音樂和音效。
你可以通過文本提示就能直接生成搖滾、爵士、電子、嘻哈、重金屬、民謠、流行、朋克、鄉(xiāng)村等20多種類型背景音樂。
例如,輸入迪斯科、鼓機、合成器、貝司、鋼琴、吉他、歡快、115BPM等關(guān)鍵詞,就能生成背景音樂。
Stable Audio官網(wǎng)地址:http://stableaudio.com
Stable Audio工作原理
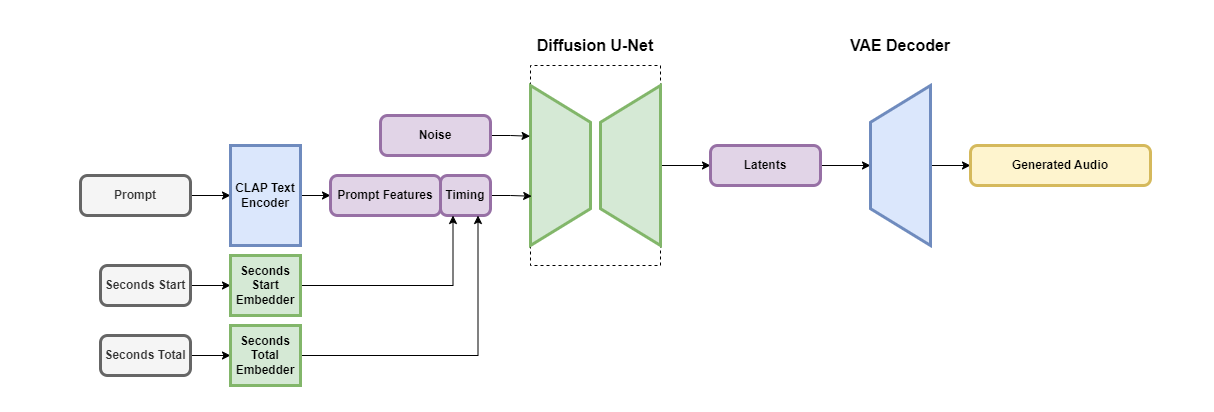
Stable Audio是一種基于文本元數(shù)據(jù)以及音頻文件持續(xù)時間和開始時間的潛在擴散模型架構(gòu),允許控制生成音頻的內(nèi)容和長度。這種額外的時序條件使我們能夠生成指定長度的音頻,直到訓(xùn)練窗口大小。
Stable Audio主要特點
- 潛在擴散模型:Stable Audio模型是由幾個不同部分組成的潛在擴散模型,包括變分自編碼器(VAE)、文本編碼器和基于U-Net的條件擴散模型。
- 高效的音頻表示:使用重度下采樣的音頻潛在表示,與原始音頻相比,可以實現(xiàn)更快的推理時間。
- 文本提示條件:為了在模型上設(shè)置文本提示,我們使用在我們的數(shù)據(jù)集上從頭開始訓(xùn)練的CLAP模型的凍結(jié)文本編碼器。
- 時序嵌入:在訓(xùn)練時,計算兩個屬性:音頻塊開始的秒數(shù)和原始音頻文件中的總秒數(shù)。這些秒數(shù)值被轉(zhuǎn)化為每秒離散的學(xué)習(xí)嵌入,并與提示令牌連接。
- 數(shù)據(jù)集:Stable Audio模型,使用了一個由超過800,000個音頻文件組成的數(shù)據(jù)集,這些文件包含音樂、音效和單一樂器莖,以及相應(yīng)的文本元數(shù)據(jù)。
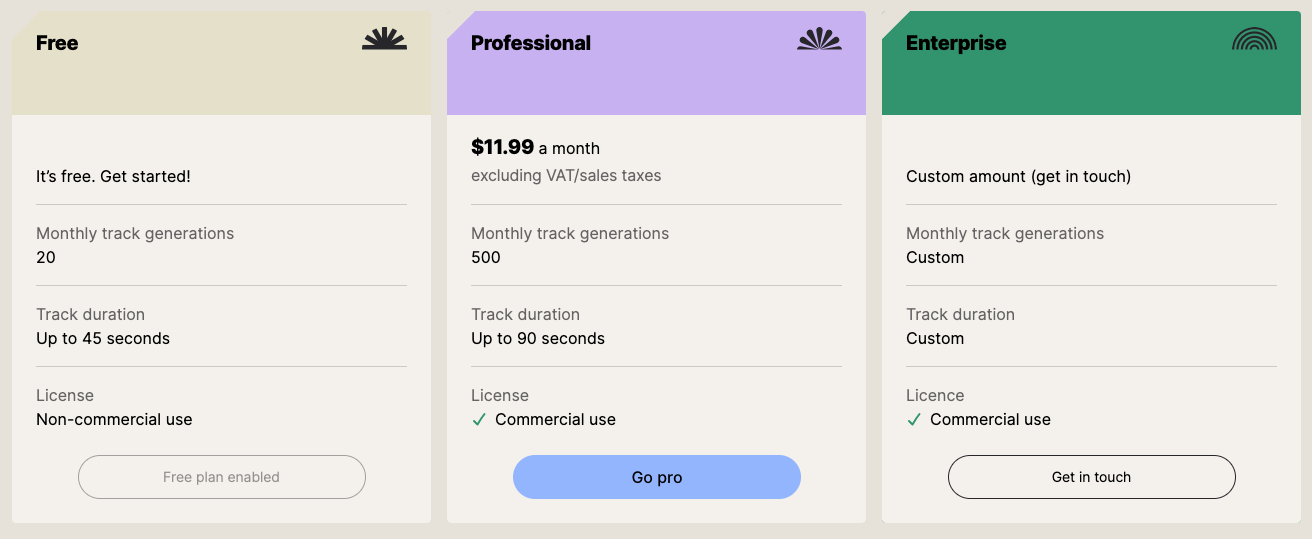
Stable Audio產(chǎn)品價格
- 免費版:每月可生成20個音樂,最大時長45秒,不能用于商業(yè)使用;
- 付費版:收費11.99美元/月,每個月可生成500個音樂,最大時長90秒,可用于商業(yè)用途。
- 企業(yè)版:與Stability AI官方聯(lián)系溝通。聯(lián)系郵箱:hey@stableaudio.com
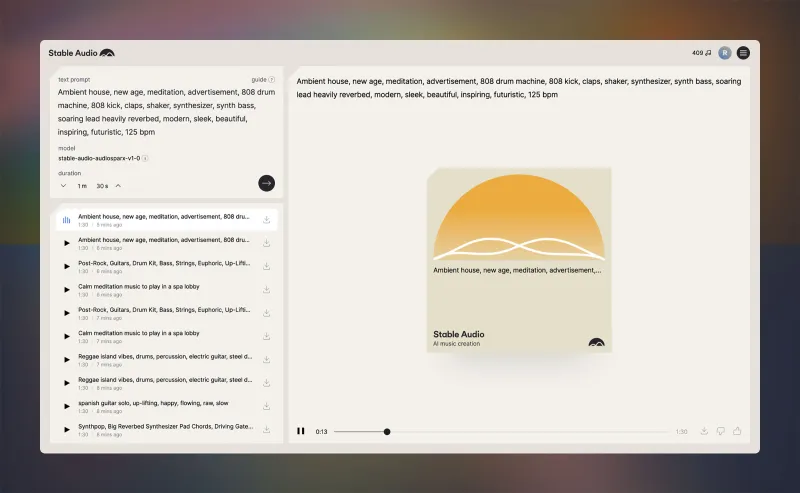
如何使用Stable Audio?
打開Stable Audio網(wǎng)站:http://stableaudio.com ,注冊一個賬號,進入使用界面。
如下圖所示,在使用界面左上方的輸入框中,輸入你想讓AI生成的音樂描述,點擊生成按鈕,即可生成音樂?。
注意?:目前用戶量比較大,有時候可能會出現(xiàn)白屏現(xiàn)象,刷新幾次就可以了。

詳細(xì)介紹:https://stability.ai/research/stable-audio-efficient-timing-latent-diffusion
?版權(quán)聲明:如無特殊說明,本站所有內(nèi)容均為AIHub.cn原創(chuàng)發(fā)布和所有。任何個人或組織,在未征得本站同意時,禁止復(fù)制、盜用、采集、發(fā)布本站內(nèi)容到任何網(wǎng)站、書籍等各類媒體平臺。否則,我站將依法保留追究相關(guān)法律責(zé)任的權(quán)利。
