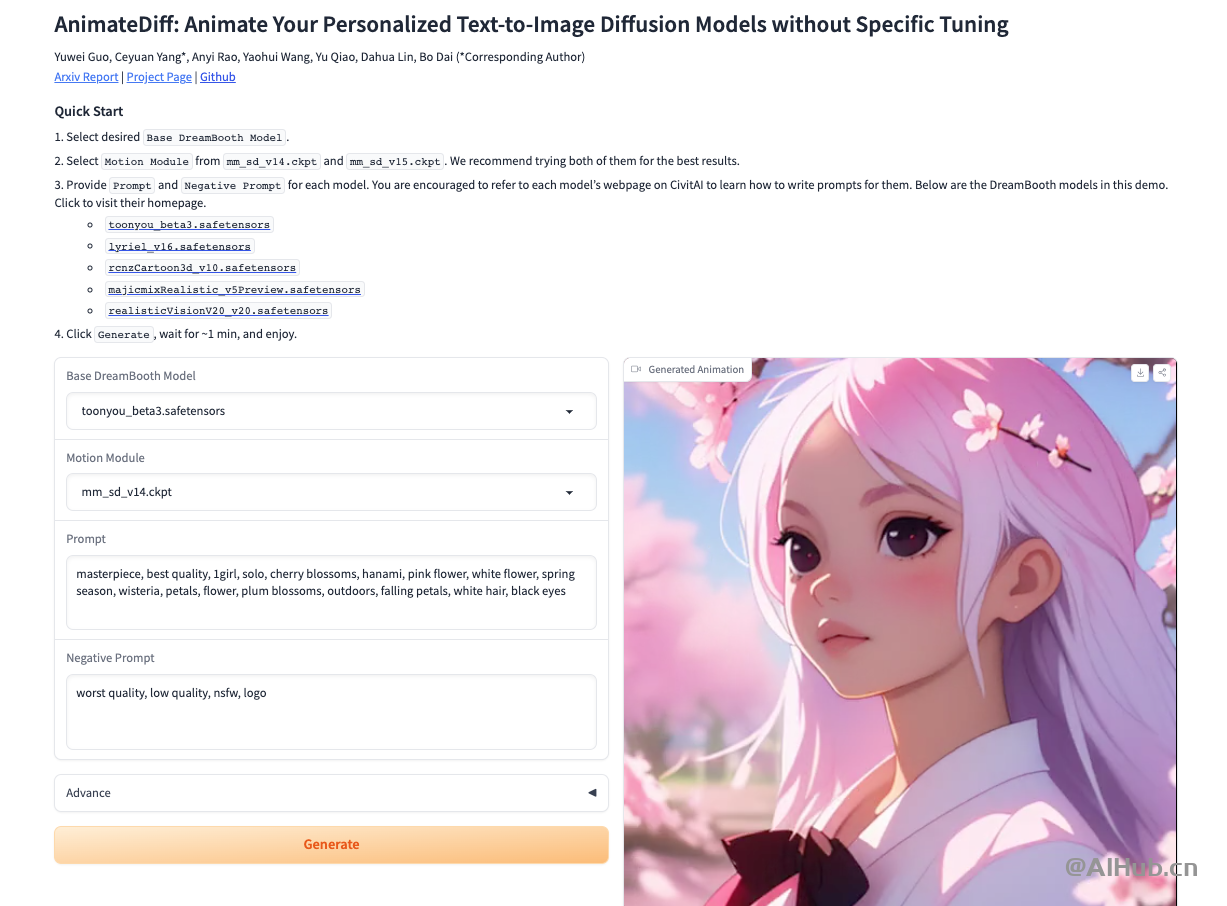
AnimateDiff是什么?
AnimateDiff 是一個(gè)能夠?qū)€(gè)性化的文本轉(zhuǎn)換為圖像的擴(kuò)展模型,它可以在無(wú)需特定調(diào)整的情況下實(shí)現(xiàn)動(dòng)畫(huà)效果。通過(guò)這個(gè)項(xiàng)目,用戶(hù)可以將他們的想象力以高質(zhì)量圖像的形式展現(xiàn)出來(lái),同時(shí)以合理的成本實(shí)現(xiàn)這一目標(biāo)。隨著文本到圖像模型(例如,Stable Diffusion)和相應(yīng)的個(gè)性化技術(shù)(例如,LoRA 和 DreamBooth)的進(jìn)步,現(xiàn)在每個(gè)人都可以將他們的想象力轉(zhuǎn)化為高質(zhì)量的圖像。隨后,為了將生成的靜態(tài)圖像與運(yùn)動(dòng)動(dòng)態(tài)相結(jié)合,對(duì)圖像動(dòng)畫(huà)技術(shù)的需求也隨之增加。
AnimateDiff可以做什么?
AnimateDiff 提供了一個(gè)有效的框架,可以為大多數(shù)現(xiàn)有的個(gè)性化文本到圖像模型提供動(dòng)畫(huà)效果,而無(wú)需為每個(gè)模型進(jìn)行特定的調(diào)整。它的核心思想是向基礎(chǔ)的文本到圖像模型中添加一個(gè)新初始化的運(yùn)動(dòng)建模模塊,并在視頻剪輯上對(duì)其進(jìn)行訓(xùn)練,以提取合理的運(yùn)動(dòng)先驗(yàn)。一旦訓(xùn)練完成,只需注入這個(gè)運(yùn)動(dòng)建模模塊,所有從同一基礎(chǔ)模型派生的個(gè)性化版本都可以立即成為產(chǎn)生多樣化和個(gè)性化動(dòng)畫(huà)圖像的文本驅(qū)動(dòng)模型。
AnimateDiff支持鏡頭平移:遠(yuǎn)近、左右、上下、旋轉(zhuǎn)等操作。
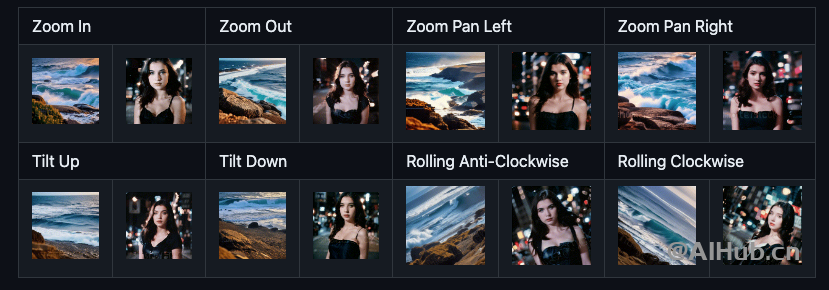
AnimateDiff使用場(chǎng)景
- 動(dòng)畫(huà)創(chuàng)建:通過(guò)文本輸入,用戶(hù)可以創(chuàng)建個(gè)性化的動(dòng)畫(huà)圖像,將靜態(tài)圖像轉(zhuǎn)變?yōu)閯?dòng)態(tài)圖像,為創(chuàng)意表達(dá)提供了一種新的方式。
- 視頻制作:為視頻制作人員提供了一種新的工具,可以將文本描述轉(zhuǎn)換為動(dòng)畫(huà)圖像,從而豐富視頻內(nèi)容。
如何使用AnimateDiff?
在線體驗(yàn):https://huggingface.co/spaces/guoyww/AnimateDiff
項(xiàng)目主頁(yè):https://animatediff.github.io/
論文地址:https://arxiv.org/abs/2307.04725
GitHub地址:https://github.com/guoyww/AnimateDiff